简介
leveldb是一款google开发的高性能,单机嵌入式k-v存储,广泛被用作各种database engine。
database文件
leveldb创建后,dbname目录下会产生一系列的小文件,由这些小文件共同存储database中的数据。
总共拥有的文件名称有:
dbname/CURRENT
dbname/LOCK
dbname/LOG
dbname/LOG.old
dbname/MANIFEST-[0-9]+
dbname/[0-9]+.(log|sst|ldb)
不同的文件根据后缀来区分功能。
LOCKdatabase文件锁,leveldb通过文件锁来避免同一个db被多次打开操作。调用DB::Open()时会先获取该文件锁。MANIFEST-XXXXX,描述文件。XXXXX => [1, n),以LOG的形式写入VersionEdit数据。CURRENT表明当前正在使用哪个MANIFEST文件LOG,LOG.old运行日志文件,当未指定options.info_log时,默认会将错误日志输出到该文件,每一次DB::Open()时,会将LOG重命名为LOG.old.log日志文件.ldbdb sst table 持久化文件,新版本的后缀,老版本后缀为.sst.dbtmp变更文件内容,中间过程中的临时文件。
实现
下面内容引自官方文档
Files
Log files
<dbname>/[0-9]+.log : db操作日志
log文件包含了最新的db操作更新,每个更新都以append的方式追加到文件结尾。当log文件达到预定大小 时(缺省大约4MB),leveldb就把它转换为一个有序表,并创建一个新的log文件。
当前的log文件在内存中的存在形式就是memtable,每次read操作都会访问memtable,以保证read读取 到的是最新的数据。
Sorted tables
<dbname>/[0-9]+.(sst|ldb) : db的sstable文件,老版本是.sst,新版本是.ldb。
sstable存储了以key排序的元素。每个元素或者是key对应的value,或者是key的删除标记(删除标记可以 掩盖更老sstable文件中过期的value)。
leveldb把sstable文件通过level的方式组织起来,从log文件中生成的sstable被放在level 0。当level 0 的sstable文件个数超过设置(当前为4个)时,leveldb就把所有的level 0文件,以及有重合的level 1文 件merge起来,组织成一个新的level 1文件(每个level 1文件大小为2MB)。
level 0的SSTable文件(后缀为.sst)和Level >1的文件相比有特殊性:这个层级内的.sst文件,两个文件 可能存在key重叠。对于Level >0,同层sstable文件的key不会重叠。考虑level >0,level中的文件的总大 小超过10^level MB时(如level=1是10MB,level=2是100MB),那么level中的一个文件,以及所有level+1 中和它有重叠的文件,会被merge到level+1层的一系列新文件。Merge操作的作用是将更新从低一级level迁 移到最高级,只使用批量读写(最小化seek操作,提高效率)。
Manifest
<dbname>/MANIFEST-[0-9]+ : DB元信息文件
它记录的是leveldb的元信息,比如DB使用的Comparator名,以及各SSTable文件的管理信息:如Level层数、 文件名、最小key和最大key等等。
Current
<dbname>/CURRENT : 记录当前正在使用的Manifest文件
它的内容就是当前的manifest文件名;因为在levledb的运行过程中,随着Compaction的进行,新的SSTable文 件被产生,老的文件被废弃。并生成新的Manifest文件来记载sstable的变动,而CURRENT则用来记录我们关心 的Manifest文件。
当db被重新打开时,leveldb总是生产一个新的manifest文件。Manifest文件使用log的格式,对服务状态的改 变(新加或删除的文件)都会追加到该log中。
Info logs
<dbname>/log : 系统的运行日志,记录系统的运行信息或者错误日志。
Others
<dbname>/dbtmp : 临时数据库文件,repair时临时生成的。
注意
上面的log文件、sst文件、清单文件,末尾都带着序列号,其序号都是单调递增的(随着next_file_number从 1开始递增),以保证不和之前的文件名重复。
这里就涉及到几个关键的number计数器,log文件编号,下一个文件(sstable、log和manifest)编号,sequence。 所有正在使用的文件编号,包括log、sstable和manifest都应该小于下一个文件编号计数器。
Level 0
当操作log超过一定大小时(缺省是1MB),执行如下操作:
- 创建新的memtable和log文件,并重导向新的更新到新memtable和log中;
- 在后台:
- 将前一个memtable的内容dump到sstable文件;
- 丢弃前一个memtable;
- 删除旧的log文件和memtable;
- 把创建的sstable文件放到level 0;
Compaction
当level L的总文件大小查过限制时,我们就在后台执行compaction操作。Compaction操作从level L中选择一个 文件f,以及选择中所有和f有重叠的文件。如果某个level (L+1)的文件ff只是和f部分重合,compaction依然选 择ff的完整内容作为输入,在compaction后f和ff都会被丢弃。
另外:因为level 0有些特殊(同层文件可能有重合),从level 0到level 1的compaction就需要特殊对待:level 0 的compaction可能会选择多个level 0文件,如果它们之间有重叠。
Compaction将选择的文件内容merge起来,并生成到一系列的level (L+1)文件中,如果输出文件超过设置(2MB), 就切换到新的。当输出文件的key范围太大以至于和超过10个level (L+2)文件有重合时,也会切换。后一个规则确 保了level (L+1)的文件不会和过多的level (L+2)文件有重合,其后的level (L+1) compaction不会选择过多的 level (L+2)文件。
老的文件会被丢弃,新创建的文件将加入到server状态中。
Compaction操作在key空间中循环执行,详细讲一点就是,对于每个level,我们记录上次compaction的ending key。 level的下一次compaction将选择ending key之后的第一个文件(如果这样的文件不存在,将会跳到key空间的开始)。
Compaction会忽略被写覆盖的值,如果更高一层的level没有文件的范围包含了这个key,key的删除标记也会被忽略。
时间
level 0的compaction最多从level 0读取4个1MB的文件,以及所有的level 1文件(10MB),也就是我们将读取14MB, 并写入14MB。
level > 0的compaction,从level L选择一个2MB的文件,最坏情况下,将会和levelL+1的12个文件有重合 (10:level L+1的总文件大小是level L的10倍;2(边界文件):level L的文件范围通常不会和level L+1的文件对齐)。 因此Compaction将会读26MB,写26MB。对于100MB/s的磁盘IO来讲,compaction将最坏需要0.5秒。
如果磁盘IO更低,比如10MB/s,那么compaction就需要更长的时间5秒。如果user以10MB/s的速度写入,我们可能生成 很多level 0文件(50个来装载5 * 10MB的数据)。这将会严重影响读取效率,因为需要merge更多的文件。
解决方法1:为了降低该问题,我们可能想增加log切换的阈值,缺点就是,log文件越大,对应的memtable文件就越大, 这需要更多的内存。
解决方法2:当level 0文件太多时,人工降低写入速度。
解决方法3:降低merge的开销,如把level 0文件都无压缩的存放在cache中。
文件数
对于更高的level我们可以创建更大的文件,而不是2MB,代价就是更多突发性的compaction。或者,我们可以考虑分区, 把文件放存放多目录中。
在2011年2月4号,作者做了一个实验,在ext3文件系统中打开100KB的文件,结果表明可以不需要分区。
| 文件数 | 文件打开ms |
|---|---|
| 1000 | 9 |
| 10000 | 10 |
| 100000 | 16 |
Recovery
db恢复的步骤:
- 首先从CURRENT读取最后提交的MANIFEST
- 读取MANIFEST内容
- 清除过期文件
- 这里可以打开所有的sstable文件,但是更好的方案是lazy open
- 把log转换为新的level 0sstable
- 将新写操作导向到新的log文件,从恢复的序号开始
GC
垃圾回收,每次compaction和recovery之后都会有文件被废弃,成为垃圾文件。GC就是删除这些文件的,它在每次 compaction和recovery完成之后被调用。
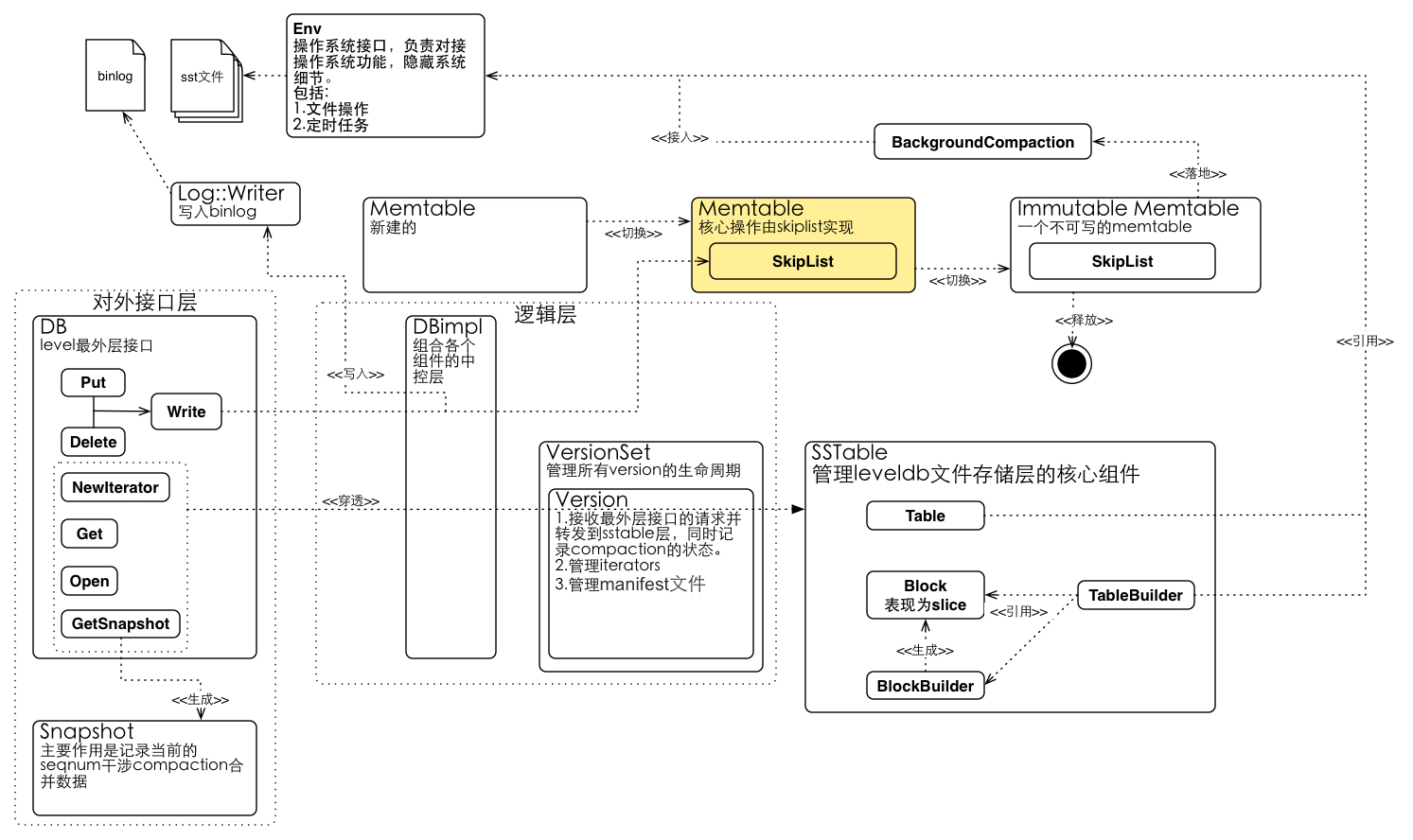
架构图
文档信息
- 本文作者:Neal Hu
- 本文链接:https://lrita.github.io/2016/12/30/leveldb-source-0/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)