在今年上海举行的SOSP 17上,微软研究院的演讲介绍了一个基于硬件加速实现的K-V存储服务。 其核心思想是依赖可编程网卡(根据论文中透露出的信息,极可能 是这一款) 将K-V存储的核心逻辑在网卡的FPGA中实现,然后FPGA通过RDMA机制访问宿主机的物理内存。 从而达到GET请求12.2亿QPS,PUT请求6.1亿QPS的超高性能。
其整体架构为:
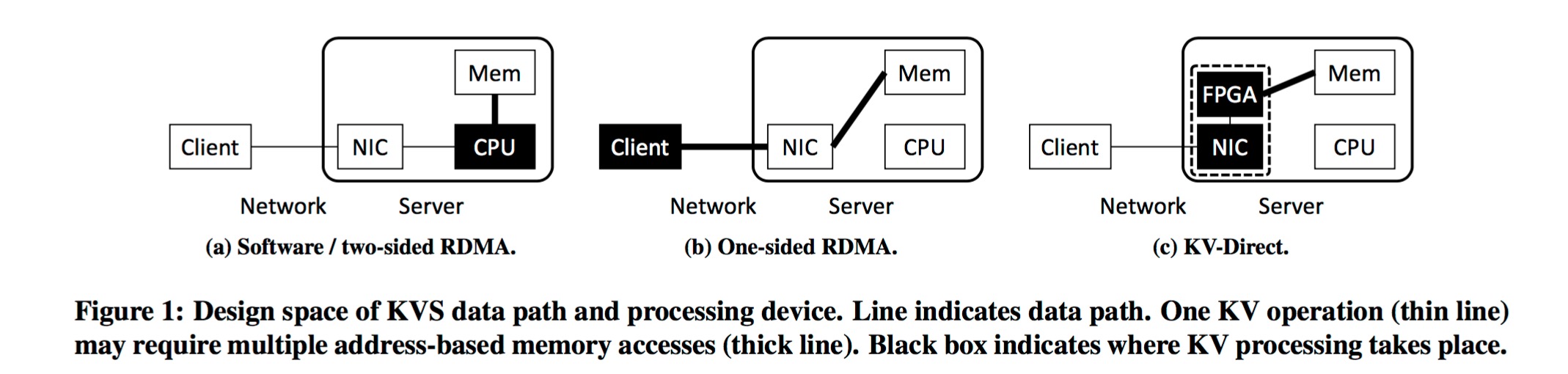
宿主机的内存分配器实现在操作系统中,然后网卡通过PCIe总线跟CPU通讯而申请、释放内存。
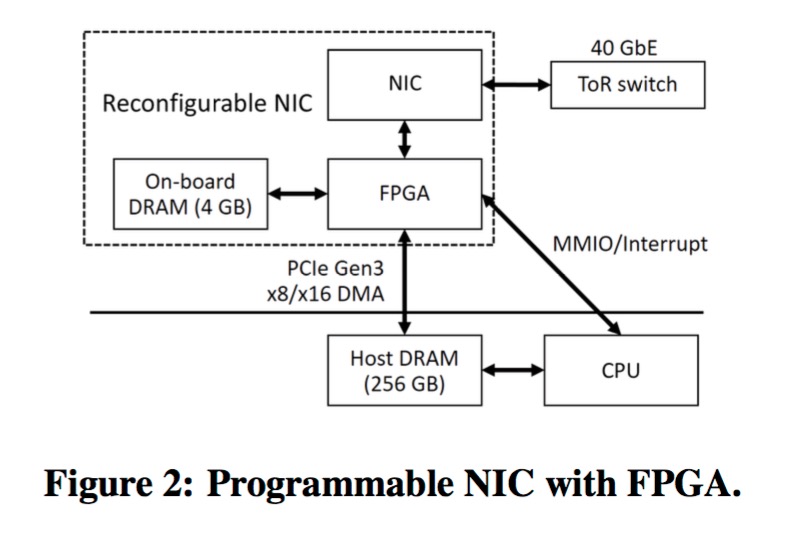
其K-V核心功能由1.1万行OpenCL代码实现。
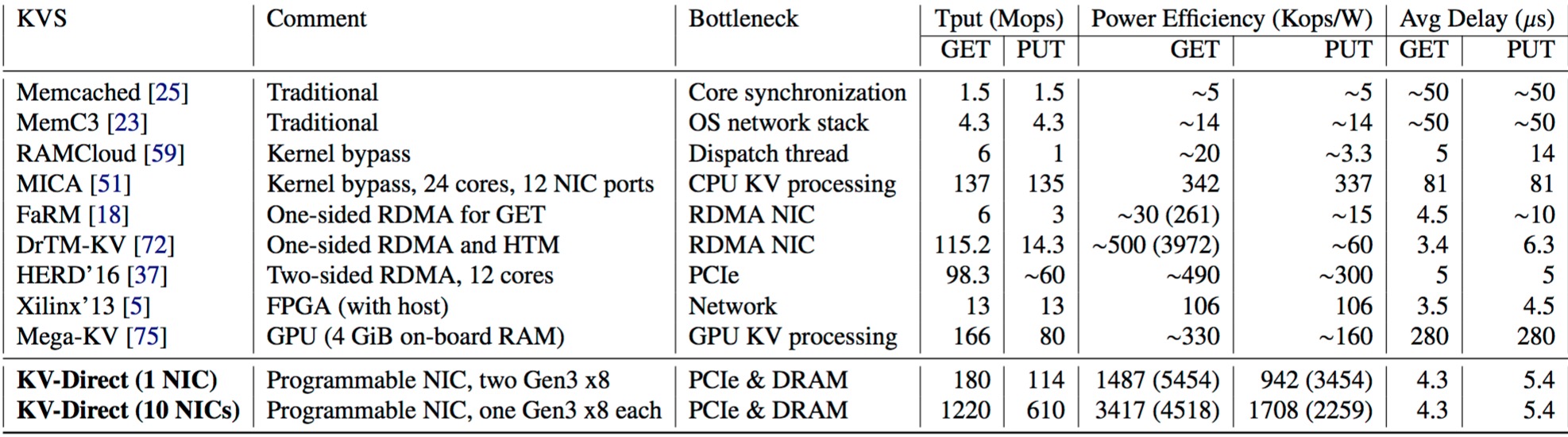
最后是和其他K-V存储的性能比较,从下图可以看出,K-V Direct的各项指标明显优于其他:
文档信息
- 本文作者:Neal Hu
- 本文链接:https://lrita.github.io/2017/10/29/K-V-Direct/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)