chainbase是符合区块链应用需求的一个事务型数据库。steemd中的chainbaseFORK自GolosChain/chainbase。
chainbase特性
- 支持多表多索引;
- 状态持久话,支持多进程;
- 嵌套式写事务,支持回滚。
实现原理
其采用Non-Volatile RAM/非易失内存中的第三种 方法:使用boost::interprocess::allocator 实现的”依赖mmap文件实现的持久化内存”内存分配作为其数据容器的内存来源,然后使用boost::interprocess中 提供的多种数据容器来实现。使用起来就像直接操作内存中的数据容器一样,只不过这些内存会通过mmap的形式持久 化到某个文件中去。
在chainbase::database中,每个表被称之为一个MultiIndex,在每个MultiIndex类实现中,需要有一个 static变量type_id类唯一标识该MultiIndex,作为查找该表的索引,比如IndexA的type_id为1,IndexB的 type_id为2,type_id的范围是0~2^16。在chainbase::database使用一个稀疏map来存储全部的MultiIndex, 该稀疏map其实就是一个std::vector<MultiIndex>。之所以称之为稀疏map,因为std::vector[type_id]的位置上存 储的就是对应的MultiIndex,因此``std::vector不是每个位置都存储着MultiIndex,除非用户注册了2^16个MultiIndex`。
每个表MultiIndex其实都是一个多索引容器,因此chainbase::database形成了多级索引。MultiIndex主要通过boost::multi_index::multi_index_container 来实现,关于这个多索引容器如何使用可以参考1、2、3、4、5、6、7 来了解。
MultiIndex中存储的Object中必须拥有一个成员chainbase::oid<Object> id,这个id作为Object的主键, oid的意思为Object ID。
例如,一个book表的实例为book_index:
struct book : public chainbase::object<0, book> {
template<typename Constructor, typename Allocator>
book(Constructor&& c, Allocator&& a) {
c(*this);
}
bool operator<(const book& b)const{return id<b.id;}
id_type id;
int a = 0;
int b = 1;
};
struct by_id{};
typedef multi_index_container<
book, // 容器中的元素
indexed_by< // 声明用户所需的索引,indexed_by中可以包含多种索引,大概支持20个不同的索引
// indexed_by中的每一项被称之为index specifier。
ordered_unique<identity<book> >, // sort by book::operator<
ordered_unique<tag<by_id>, member<book,book::id_type,&book::id> >,
// ordered_unique 声明使用的索引类型,从名
// 称上就可以理解该索引的作用。除此之外还有:
// sequenced、random_access、hashed_unique、
// hashed_non_unique、ranked_unique、
// ranked_non_unique。
// 其中的member为构建的索引使用了对应类的成
// 员变量,同时还支持函数索引、联合索引等功
// 能。
// 该索引的意思为,按照book的id字段来进行排
// 序,顺序为std::less<book::id_type>
// tag<by_id>的意思为,给该索引增加一个标识
// 随后可以根据该标识来使用这个索引。
ordered_non_unique< BOOST_MULTI_INDEX_MEMBER(book,int,a) >, // BOOST_MULTI_INDEX_MEMBER 是一个宏,其
// 展开形式为member<book, int, &book::a>
ordered_non_unique< BOOST_MULTI_INDEX_MEMBER(book,int,b) >
>,
chainbase::allocator<book> // 使用chainbase::allocator使得该容器中的元素也能分配在mmap的内存中
> book_index;
CHAINBASE_SET_INDEX_TYPE(book, book_index)
如上面的例子,我们可以为book添加多种索引,索引的种类可以参考Index types。 但是book中并没有存在type_id这个表标识符,因为book继承自chainbase::object,chainbase::object是 一个辅助基类,帮助生成type_id这个表标识符和id_type类型声明,其继承声明chainbase::object<0, book>中 的第一个参数0,的意思就是生成的type_id这个表标识符的值为0。因此我们声明自己的表时,也不需要进行声明额外 的成员,直接继承该辅助类即可。
用户通过chainbase操作每个表中数据的过程是,先根据其对象中的type_id从chainbase内部的稀疏map中获取到 对应的book_index,然后再根据book_index中声明的多种索引方式来操作book,用图像表述为:
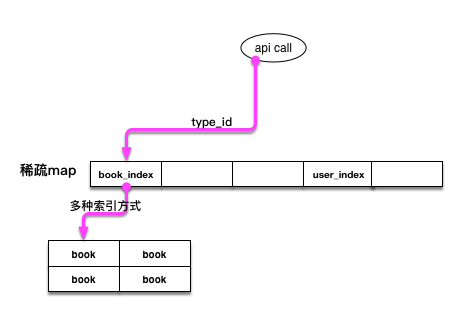
最后一句宏CHAINBASE_SET_INDEX_TYPE(book, book_index)的含义是,将book声明成book_index的别名,建立绑 定关系。因为在chainbase对外的API中,会尽量屏蔽掉boost::multi_index::multi_index_container这个容器的 相关操作,减少用户的心智负担,因为要让用户搞清,什么时候需要用到book,什么时候需要用到book_index,确 实比较麻烦。在API层面上,用户基本上只需要用到book。
在database中,还会使用generic_index 对MultiIndex进行封装,例如generic_index<book_index>。generic_index这个封装主要实现了事务、自增主键 等逻辑。这部分逻辑比较多,因此将generic_index逻辑分散在database的API中进行分析。
chainbase缺陷
- 缺乏并发控制:其内部没有并发控制,需要用户在外部自己维护并发问题,如果跨进程共享,用户需要通过跨进程 锁来保护。
- 持久化数据格式不跨平台:如果将一个机器上的数据库文件拷贝到其他架构的机器上时,可能产生不兼容的问题。
- 缺乏宕机一致性:其没用采用一般数据库常用的
WAL技术,在变更数据的过程中,内存的同步完全依赖操作系统 的刷新机制;当数据变更完成,其采用异步同步(async flush)策略,因此在这2步过程中,系统异常宕机,其数据可 能产生损坏。 - 容量有限:其采用
mmap机制实现内存的持久化,因此其存储容量很难超过机器内存的容量。
database api
chainbase::database基本方法如下所述,在注释中有简单说明,如果内容比较多的函数,在更下面有详细的说明:
class database
{
public:
// 启动db
void open( const bfs::path& dir, uint32_t flags = 0, uint64_t shared_file_size = 0 );
// 解除该database的文件映射,关闭文件;
void close();
// 同步mmap的内存到文件(msync)
void flush();
// 释放mmap内存,删除文件,等于是清空了该database。
void wipe( const bfs::path& dir );
// 设置标识符,在一些操作时,是否需要锁
void set_require_locking( bool enable_require_locking );
// session是abstract_session的一个容器,用来存储实际的undo会话(事务)
// 后面再讲
class session;
// 启动一个undo会话(事务),如果enabled=true,实际启动一个undo会话,
// 否则没有任何影响,返回一个空session。
// 与事务相关,留在后面再将
session start_undo_session( bool enabled );
// 获取最小的undo索引的变更号
// 与事务相关,留在后面再将
int64_t revision() const;
// 对database中所有undo会话执行undo命令
// 与事务相关,留在后面再将
void undo();
// 合并临近的变更
// 与事务相关,留在后面再将
void squash();
// 对database中所有undo会话执行提交命令
// 与事务相关,留在后面再将
void commit( int64_t revision );
// 对database中所有undo会话执行undo_all命令
// 与事务相关,留在后面再将
void undo_all();
// 对database中所有undo会话执行set_revision命令
// 与事务相关,留在后面再将
void set_revision( int64_t revision );
// 增加一张表,注册MultiIndexType类型的index,例如book_index
template<typename MultiIndexType>
void add_index();
// 获取mmap内存管理器的handle
auto get_segment_manager();
// 获取剩余内存
size_t get_free_memory() const;
// 判断MultiIndexType类型的index是否存在,去稀疏map中进行查找,例如book_index
template<typename MultiIndexType>
bool has_index() const;
// 获取执行MultiIndexType类型的index,不可修改。如果该类型的index之前未进行注册,则会抛出异常
// 例如book_index
template<typename MultiIndexType>
const generic_index<MultiIndexType>& get_index() const;
// 获取执行MultiIndexType类型的index,与get_index()相同,获取的表是可变的。
template<typename MultiIndexType>
generic_index<MultiIndexType>& get_mutable_index();
// 调用指定类型MultiIndexType的index的add_index_extension方法,例如book_index
template<typename MultiIndexType>
void add_index_extension( std::shared_ptr< index_extension > ext );
// 获取指定类型MultiIndexType的Index表,然后根据tag<ByIndex>来获取该表的索引。
// 例如:get_index<book_index, by_id>()
template<typename MultiIndexType, typename ByIndex>
auto get_index() const;
// 根据索引tag来查找响应内部对象,CompatibleKey是查找时的比较器。
// 其会根据绑定关系,从ObjectType得到MultiIndexType,然后在该表下获取指定tag的的索引,
// 然后调用索引的find方法进行查找。未找到时返回nullptr。
// 索引的find方法是一个模板,支持多种查找方法,CompatibleKey可以是一个具体的类型,也
// 可以是一个仿函数。
// 例如:find<book, by_id, book::id_type>(1);
template< typename ObjectType, typename IndexedByType, typename CompatibleKey >
const ObjectType* find( CompatibleKey&& key ) const;
// 通过ObjectType的oid(主键)来查找该Object,前提是该Object对应的MultiIndex在声明时,建立
// oid的索引。未找到时返回nullptr。
template< typename ObjectType >
const ObjectType* find( oid< ObjectType > key = oid< ObjectType >() ) const;
// 调用find,为找到时抛出异常
template< typename ObjectType, typename IndexedByType, typename CompatibleKey >
const ObjectType& get( CompatibleKey&& key ) const;
// 调用find,为找到时抛出异常
template< typename ObjectType >
const ObjectType& get( const oid< ObjectType >& key = oid< ObjectType >() ) const
// 修改ObjectType对应表中obj对象,修改失败时抛出异常。会将修改前的对象记录在undo栈中。
// Modifier为一个仿函数,可以参考:
// http://www.boost.org/doc/libs/1_66_0/libs/multi_index/doc/reference/ord_indices.html#modify
template<typename ObjectType, typename Modifier>
void modify( const ObjectType& obj, Modifier&& m );
// 删除ObjectType对应表中obj对象。会将修改前的对象记录在undo栈中。
template<typename ObjectType>
void remove( const ObjectType& obj );
// 在ObjectType对应的表中创建一个ObjectType对象,Constructor是ObjectType的构造器。
// 会将创建对象记录在undo栈中。
template<typename ObjectType, typename Constructor>
const ObjectType& create( Constructor&& con );
// 在持有database内部读锁的情况下,执行lambda
template< typename Lambda >
auto with_read_lock( Lambda&& callback, uint64_t wait_micro = 1000000 );
// 在持有database内部写锁的情况下,执行lambda
template< typename Lambda >
auto with_write_lock( Lambda&& callback, uint64_t wait_micro = 1000000 );
// 对每个表执行extension
template< typename IndexExtensionType, typename Lambda >
void for_each_index_extension( Lambda&& callback ) const;
// 获取全部注册的MultiIndexType列表
typedef vector<abstract_index*> abstract_index_cntr_t;
const abstract_index_cntr_t& get_abstract_index_cntr() const;
};
open
steem::chainbase::database使用了默认的构造函数,因此该类实例化时,并不会有任何作用,其启动入口为database::open。 基本流程就是:
- 创建database数据目录,然后在目录中创建数据库持久化文件
shared_memory.bin,然后将该文件扩容到指定大小 (默认大小为54G,可以使用配置项中的shared-file-size进行配置) - 然后将该文件通过
boost::interprocess::managed_mapped_file来管理,由成员变量_segment负责维护。还有 一个相同的成员变量_meta目前是无用的。 - 然后存储一个
environment_check用以记录该数据库生成的环境,用以启动时校验,因为从设计上,数据库文件能不能直接搬运的。
add_index
add_index向database中添加一张表(这里的index就相当于SQL中的表),并且相同的表不能重复添加,否则会 抛出异常。其原型为:
template<typename MultiIndexType>
void add_index();
这里的MultiIndexType就是前面原理中举例的book_index,其要满足原理中讲的那些要求。
在该函数中,其会从mmap的内存中分配,构造出generic_index<MultiIndexType> 该类是MultiIndexType的包装,在generic_index实现了很多index的基本操作,这个留在后面再讲。
该函数会将generic_index<MultiIndexType>再用index 包装成index<generic_index<MultiIndexType>>,然后存储在chainbase的稀疏map中。
实例:
db.add_index< book_index >();
db.add_index< book_index >(); // 第二次添加索引会抛出std::logic_error异常
with_read_lock和with_write_lock
这2个方法的意义为在持有database中读写锁的情况下执行一些回调函数,意为同步一些并发处理的逻辑。但是这2个 方法本质上都是完全错误的实现。
首先,database中的读写锁采用了boost::interprocess::interprocess_sharable_mutex的实现,并且database 中的数据结构都是跨进程的,并且文档中也说明了该实现是跨进程 的。但是该锁并没有分配在进程间共享内存上,也就是说该锁并没有跨进程并发控制的能力。此处应该是一个bug。
其次,wait_micro参数不为0时,其会调用等待超时LOCK的逻辑,当一个线程等待获取锁超时时,其会跳过当前的锁, 去获取另外一个新锁…,这是什么狗屁逻辑,作者的初衷是好的,避免一个线程获取锁后意外退出,造成该锁不会被 释放,从而死锁。但是这个实现实在过于粗暴。其默认值为1秒钟,如果一个进程持有锁超过1秒钟,则该方法的并发 控制会完全失效,database中的内存分配器等实现都是依赖外部并发控制的。而且很多操作会涉及磁盘等慢设备,偶 尔超过1秒也是存在可能性的。这点需要注意,可能你某次发现database意外损坏就是可能由于其并发处理问题引起 的。
create
// 在ObjectType对应的表中创建一个ObjectType对象,Constructor是ObjectType的构造器。
// 会将创建对象记录在undo栈中。
template<typename ObjectType, typename Constructor>
const ObjectType& create( Constructor&& con );
该函数会先找到ObjectType对应的generic_index<MultiIndexType>表,然后调用其emplace 方法来创建出ObjectType。在该函数中,会将ObjectType内置的主键chainbase::oid<Object> id加1,这样保证 该表中每个ObjectType的主键值都不同,也避免用户在外部维护这段逻辑。然后调用generic_index<MultiIndexType>::on_create 将该次创建记录在启动的undo事务中。
示例:
const auto& new_book = db.create<book>([](book& b) {
b.a = 3;
b.b = 4;
});
get
// 调用find,为找到时抛出异常
template< typename ObjectType >
const ObjectType& get( const oid< ObjectType >& key = oid< ObjectType >() ) const
示例:
// 获取oid==0的book对象
const auto& copy_new_book = db2.get( book::id_type(0) );
modify
// 修改ObjectType对应表中obj对象,修改失败时抛出异常。会将修改前的对象记录在undo栈中。
// Modifier为一个仿函数,可以参考:
// http://www.boost.org/doc/libs/1_66_0/libs/multi_index/doc/reference/ord_indices.html#modify
template<typename ObjectType, typename Modifier>
void modify( const ObjectType& obj, Modifier&& m );
该函数会先找到ObjectType对应的generic_index<MultiIndexType>表,然后调用其modify 方法来修改对应的ObjectType。在该函数中,其会先调用generic_index<MultiIndexType>::on_modify 将修改前的ObjectType存储在undo事务中,然后再调用容器boost::multi_index::multi_index_container::modify, 修改对应的ObjectType。
示例:
db.modify( new_book, [&]( book& b ) {
b.a = 5;
b.b = 6;
});
remove
// 删除ObjectType对应表中obj对象。会将修改前的对象记录在undo栈中。
template<typename ObjectType>
void remove( const ObjectType& obj );
该函数会先找到ObjectType对应的generic_index<MultiIndexType>表,然后调用其remove 方法。在该函数中,其会先调用generic_index<MultiIndexType>::on_remove 将修改前的ObjectType存储在undo事务中,然后调用boost::multi_index::multi_index_container::erase将其删除。
事务支持
chainbase::database内部使用generic_index<MultiIndexType>实现了对写操作事务性的支持。首先列出该实现的提 供的特性:
database内部每个表generic_index<MultiIndexType>支持一个全局事务。- 该事务只是简单支持了回滚操作。
- 没有任何隔离性
在generic_index<MultiIndexType>存储着2个成员:
_revision事务号,每开启一个新的事务该值加1,然后分配给新开启的事务_next_id主键id,每创建一个ObjectType该值加1,然后分配给新创建的对象
用户可以调用
auto session = database::start_undo_session(true);
来开启一个undo事务。该方法会调用database中每一个表的generic_index<MultiIndexType>::start_undo_session 方法,该方法创建一个新的session,同时再generic_index<MultiIndexType>内部的undo_state栈 上压入一个对象。undo_state 用以记录在该session被创建后,数据的变更情况。
在用户创建session后,对chainbase::database中该表generic_index<MultiIndexType>的每一个写操作会触发 回调on_create、on_modify和on_remove,这几个回调函数会将每个ObjectType的变更情况记录在undo_state栈 上。
用户也可以同时创建多个session。
auto session0 = database::start_undo_session(true);
/* do something ... */
auto session1 = database::start_undo_session(true);
session在的实际作用与std::lock_guard实现相似, 使用RAII机制构建一个作用域控制 类。session主要提供3个方法push()、squash()、undo() ,如果session没有被调用push()方法,则session析构时,会自动调用generic_index<MultiIndexType>的 undo()方法,撤销用户之前的修改。
generic_index<MultiIndexType>提供了一些关于事务的API分别提供session和database调用:
undo
void undo() 撤销undo_state栈栈顶的undo_state中记录的全部变更操作。同时回滚前面提到的_revision和_next_id。
undo_all
undo_all 撤销undo_state栈中全部的变更操作。
revision
int64_t revision() 返回当前的_revision。
squash
void squash() 合并undo_state栈末尾2个undo_state中的全部变更记录。 比如前面举例的session0和session1同时存在时,会有2个undo_state,此时调用squash,将其合并。
但是这个方法在实现上也存在bug。
auto session0 = database::start_undo_session(true);
// do modify 0
{
auto session1 = database::start_undo_session(true);
// do modify 1
auto session2 = database::start_undo_session(true);
// do modify 2
db.squash(); // 合并session1和session2
}
// 从设计思想,此处应该只回滚掉modify 1和2才是正确的实现,
// 不幸的,此处实际上会回滚掉modify 0,1,2
commit
void commit( int64_t revision ) 提交修订号小于revision的全部修改,这部分修改不再会被回滚。
总结
以上就是对libraries/chainbase流水账般的分析,在steemd中并没有直接使用了chainbase::database,而是 又封装了一层,这个留在下篇进行分析。
文档信息
- 本文作者:Neal Hu
- 本文链接:https://lrita.github.io/2018/03/22/steemd-source-2/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)