介绍
HASH ARRAY MAPPED TRIE(HAMT)是一种哈希数据结构1,速度高效而且更小的空间开销。而且避免了传统的哈希结构的问题:
- 创建一个经验值的哈希表
- 哈希表扩缩容
HAMT的树型结构如下图所示:
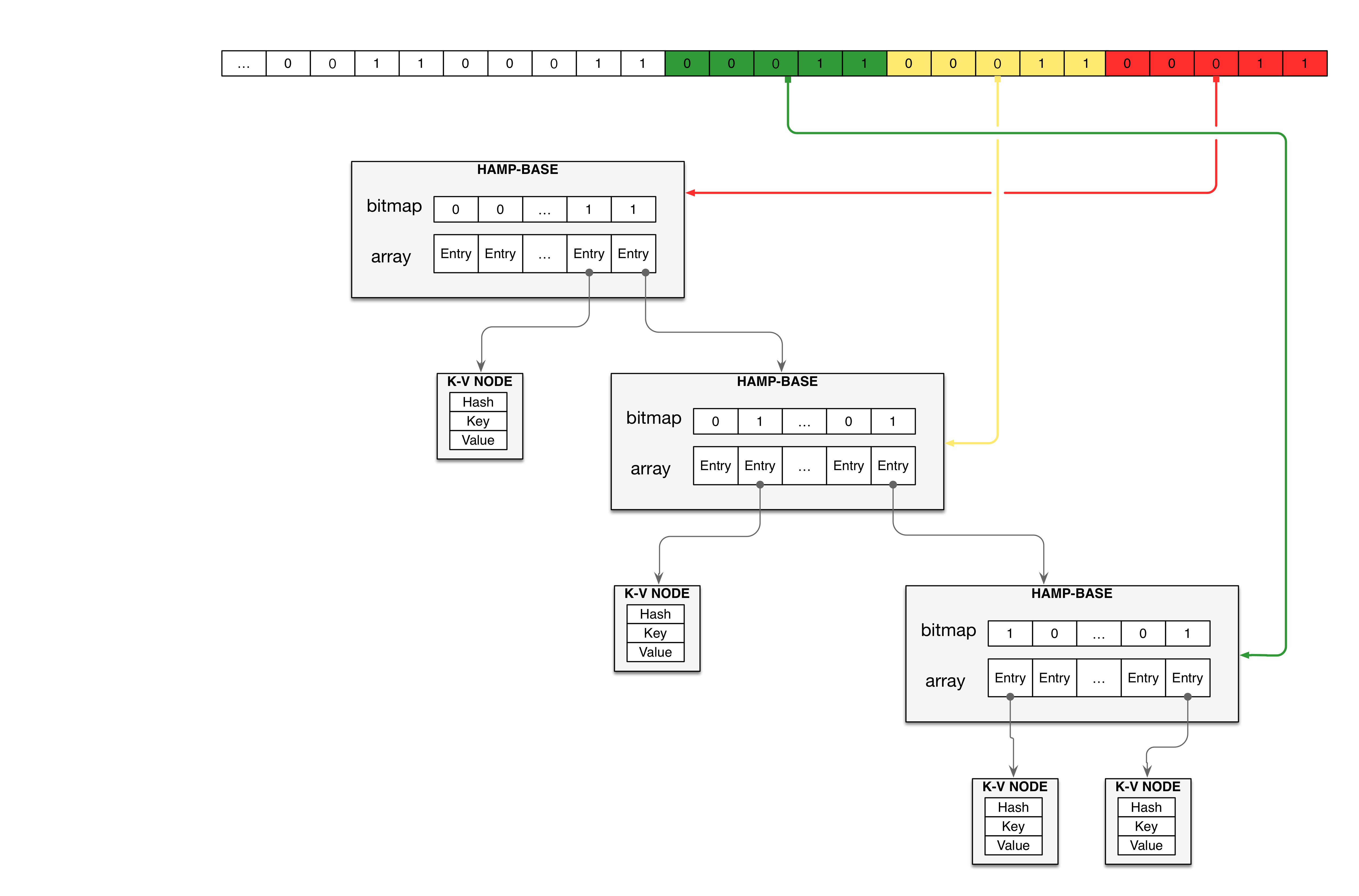
HAMT主要根据hash值长度(uint32/uint64)的不同,主要实现有HAMT-32和HAMT-64,下面的叙述以HAMT-64为模板。
对于任意Key,可以计算一个64bit(8byte)的哈希值。然后我们使用这个64bit的哈希值来构建TRIE。其中TRIE的每一层使用64bit哈希值中的tbit,从高位还是低位截取都可以,图中表示的为从低位开始截取。与这tbit对应的,在TRIE的每一层,我们提供一个2t大小的bitmap和array存储下一级指针,则生成的TRIE最大深度为floor(64/t)(通常t至少为5,这样bitmap为32bit,即一个uint32,对应各种位运算来说比较方便,而且其对应的32长度的指针数组也不会造成太大的空间浪费,这样对应的TRIE的最大深度为12)。
查询
当查询时,从TRIE的根节点开始,每层取哈希值对应的level * t到 (leve+1) * t位的bit值为该层的索引index。然后在该层的bitmap的第index位进行判断:
- 如果是0则表示没有后继,说明不存在目标Key;
- 如果是1,则从该层指针数组中取得指针对应的节点:
- 如果指针对应的节点为
K-V节点,如果K-V节点中的Key与目标Key相同,则查找到了对应的Key; - 如果
K-V节点中的Key与目标Key不相同,则说明不存在目标Key
- 如果指针对应的节点为
插入
当插入新值时,与查询相似,根据插入Key对应的哈希值来逐层查询TRIE,
- 当对应层的bitmap对应的
index为0时,则创建一个K-V节点,将插入值的哈希值、Key、Value存储在K-V节点中,然后将K-V节点指针存储在该层指针数组的第index位置,然后插入成功。 - 当对应层的bitmap对应的
index为1时,则从指针数组取出对应的指针进行判断:- 如果是
TRIE节点指针,说明还有下一层,则递归进行插入。 - 如果是
K-V节点则先对哈希值进行判断,如果哈希值不同且为到达最大深度时,则创建一个TRIE节点,将原来的K-V节点和待插入值的K-V节点插入到新建的TRIE节点中,然后把新建的TRIE节点取代原来指针数组的第index位置,这样就使TRIE增长了一层,如下图所示。 - 如果是
K-V节点且达到了最大深度、或者对应的哈希值相同,则说明发生了哈希碰撞,则此时使用链表法,将发生碰撞的K-V节点使用链表级联。
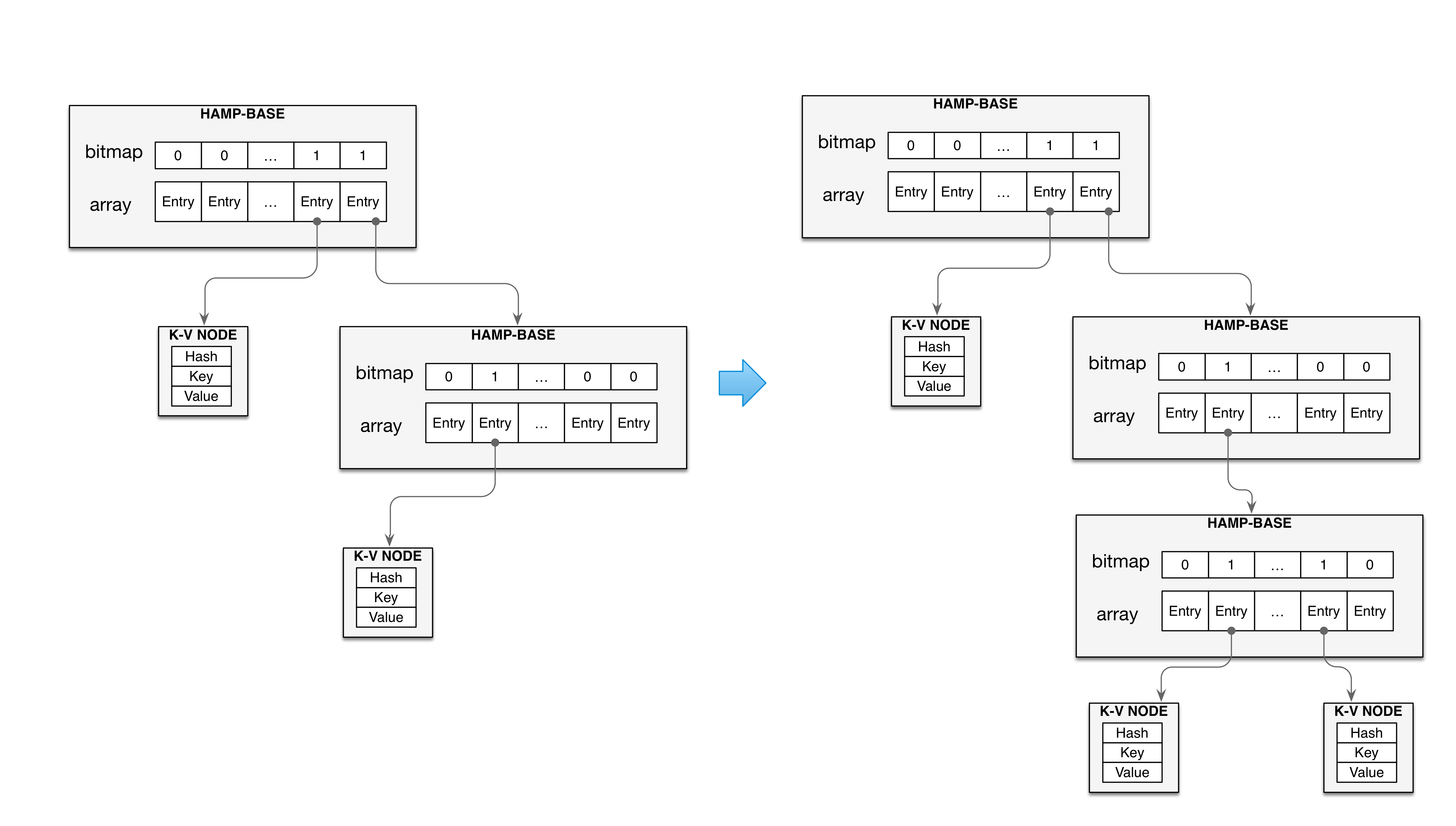
- 如果是
删除
删除其实是插入的反操作,当查找到对应的Key时,删除其对应的K-V节点,清除bitmap的对应位,然后还需一步:TRIE的收缩。此时判断对应level的TRIE节点下bitmap中1的个数,如果bitmap只有1位置为1,且是一个K-V节点时,则可以删除本level的TRIE。这个过程是上图的反向操作,从右向左看即是。
HAMT的优点
哈希利用率
从HAMT的结构看出,其比较一般的哈希表来说,其更加充分利用了哈希值的各个bit,一般的哈希表大小有限,通常采用哈希值对表长度取余的方式(Index = HashValue % Length),只能使用哈希值的很少几位,因此发生哈希碰撞的概率更高。如果取上述t为5的话,HAMT-32可以使用哈希值的30bit,HAMT-64可以使用哈希值的60bit。也可以看出,HAMT-64的哈希碰撞概率比HAMT-32更低。
空间利用率
当哈希表的填充率很高时,HAMT的空间利用率比一个的开放地址法的哈希表更高。
但是当哈希表很稀疏时,每个TRIE节点的指针数组的填充率就会下降,导致空间利用率下降,因此TRIE节点还有一个变种实现,稀疏节点:每个TRIE节点下的指针数组不再是固定2t大小的,因为在哈希表很稀疏的清下,会浪费很多空间。则我们事每个TRIE节点的指针数组为变长数组,当TRIE节点的bitmap只有一位为1时,则,指针数组的长度为1,当TRIE节点的bitmap只有两位为1时,则指针数组的长度为2,如下图所示:
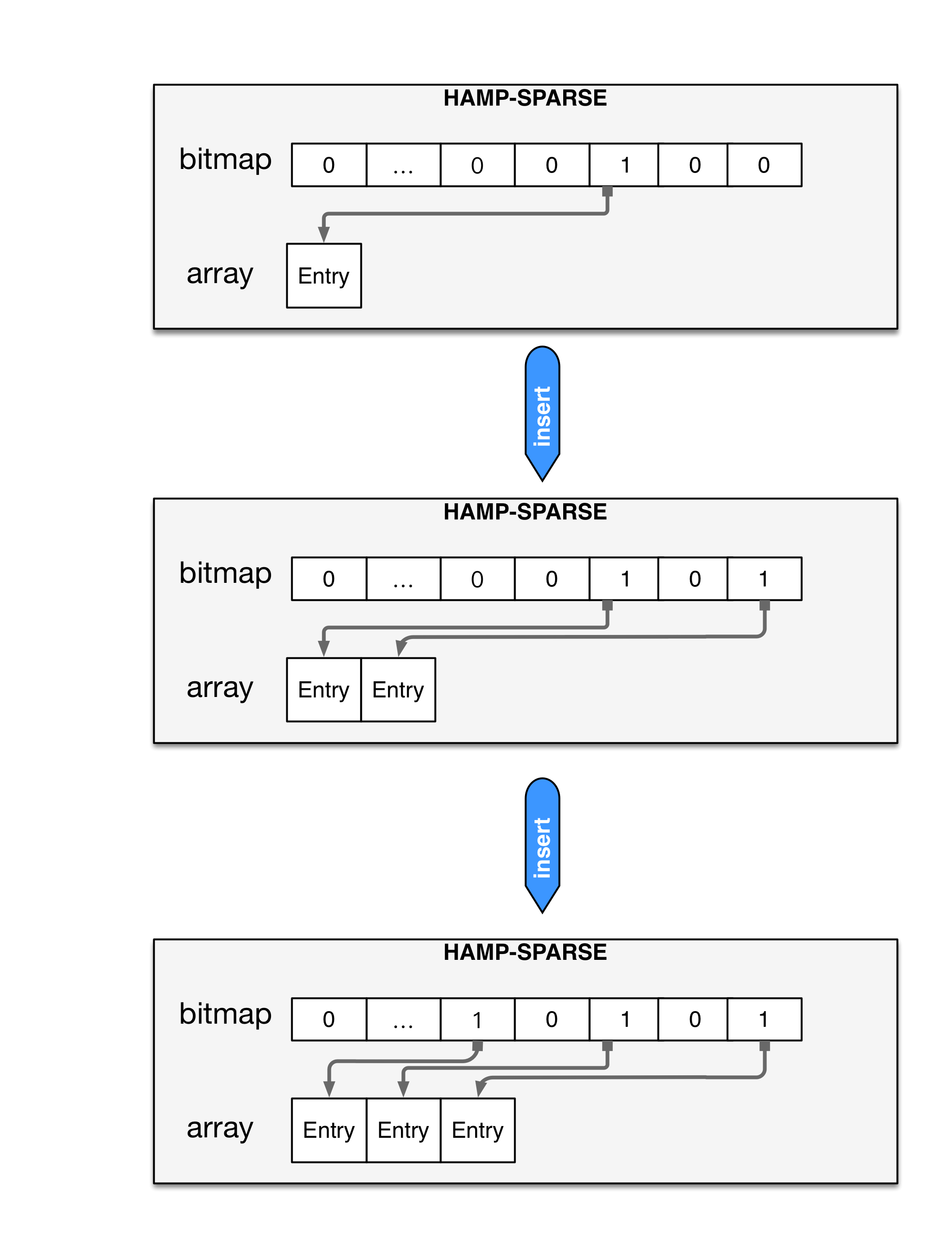
我们可以很容易得出指针数组位置与bitmap的映射关系为:
- 指针数组的长度为bitmap中置1的bit个数
- bitmap中
ibit为1时,其对应指针数组中的位置为x,则x等于(bitmap & ( 1<<i - 1))中1的个数
这里可以看到,2条对应关系都需要用到计算bitmap中1的个数,这个方法有一个高效算法,在golang的math/bits中就有实现。
当然使用这种实现,效率上比直接分配固定大小的TRIE节点略低一些,但是有起高效的算法支持,效率上的损失不会特别大。当然还有一种方法就是采用自省地混合实现。自省是指,HAMT内部自己可以通过观察TRIE节点的填充率来决定使用哪个实现,在go-hamt2就采用了这种实现。
不可变性
根据HAMT的层次结构,很容易实现不可变的数据结构,这样非常利于实现一种持久化存储结构,比如BTREE。
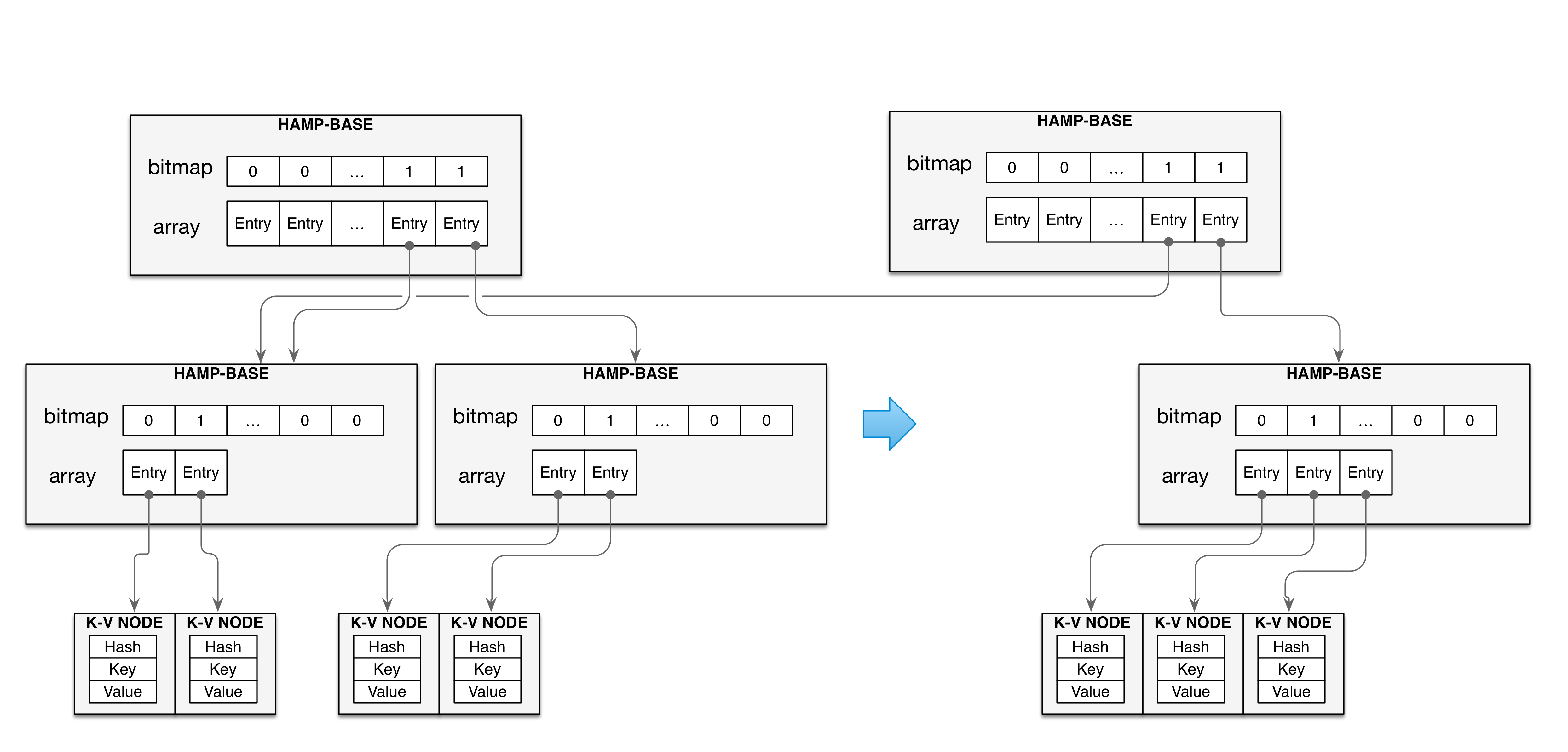
从上图可以看出,HAMT在一次更新操作后,只需要修改沿途的几个TRIE节点,未触及的路径可以直接引用,这样我们可以生成沿途节点的副本,很容易就实现一个COW的实现。
文档信息
- 本文作者:Neal Hu
- 本文链接:https://lrita.github.io/2018/07/15/hash-tree-hamp/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)