log structured merge tree1已经是现代数据库常用的一种数据结构,其优点就是能够将全部操作都转化为写入,从而使磁盘的连续写入优势发挥最大等。但是会带来写放大和空间放大。但是读放大、写放大和空间放大是一对矛盾体2 3 4。因此,由于有着不同的取舍,就有了不同的compaction算法。使用不同的compaction算法,导致的空间放大会有不同,但是BigTable, HBase、Cassandra、LevelDB、RocksDB等都使用了leveled compaction5,则我们根据leveled compaction算法来谈谈空间放大。
leveled compaction拥有最小的空间放大,但是带来很大的写放大和读放大。
空间放大产生的原因
根据LSM的定义,其将所以的操作都转化为一个新的op写入存储结构,增删改查都是一个对应的op,当查找对应的KEY时,就查找对应的最新的op,如果未找到或者最新的op是“删除”,则该KEY不存在,否则返回最新op对应的值。因此一个KEY在存储中会对应多个op,从而导致实际使用的磁盘空间大于存储中的数据量大小,也就是空间放大。
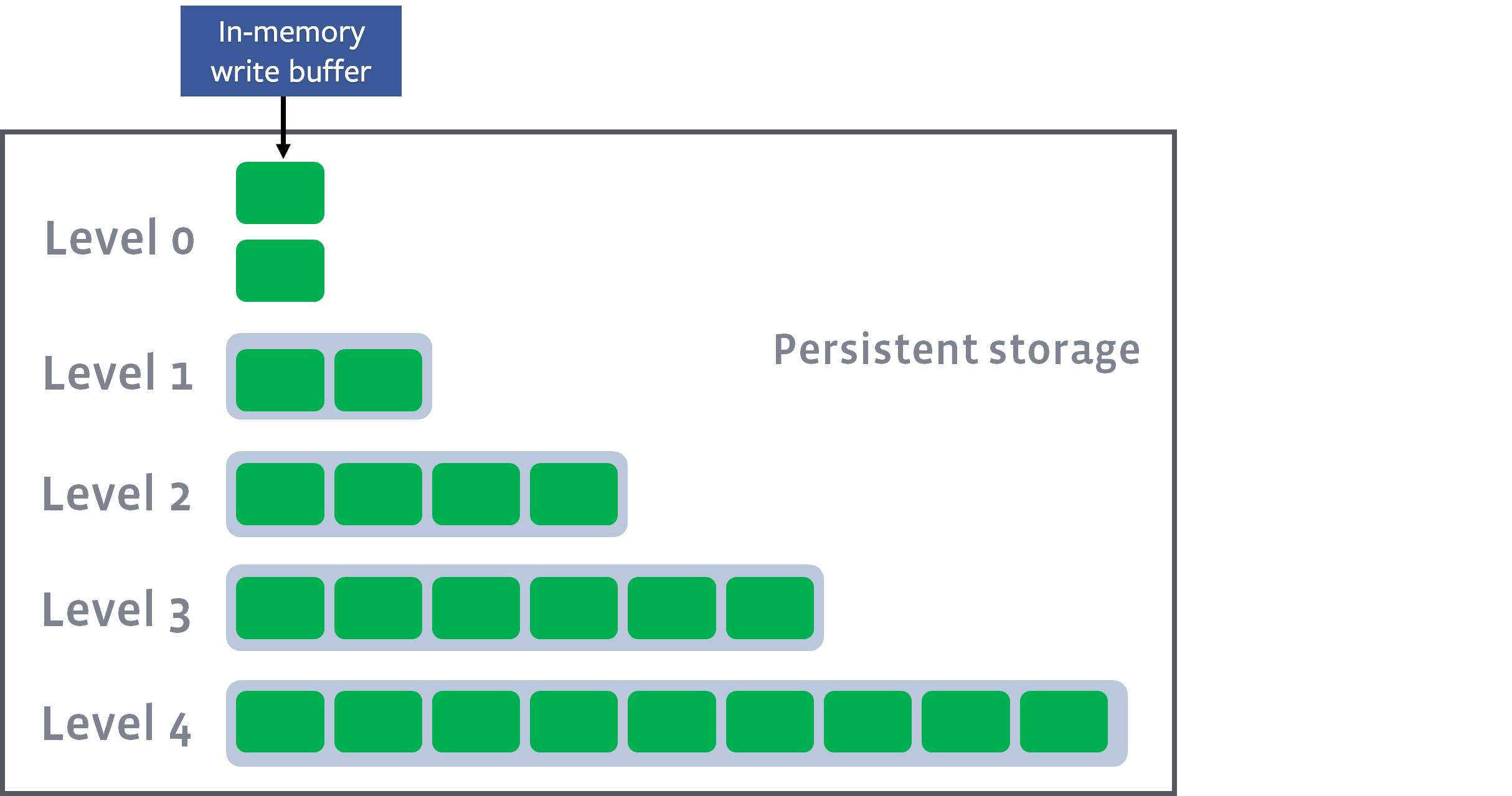
其中省略一些细节,为了节省存储空间,将这些op按层级组织起来,然后从上到下,每层的存储容量依次增加。通常规定\(L _ {n+1}\)的容量是\(L _ n\)的增长系数倍,这个值通常是10:
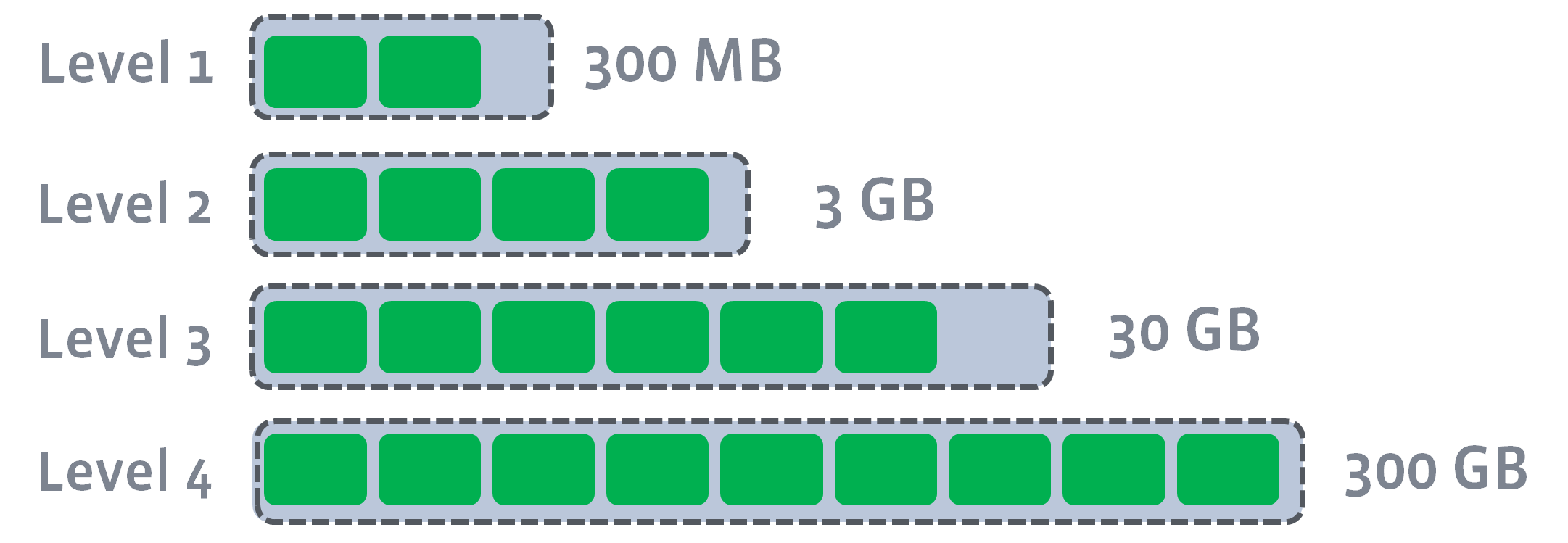
按照op的写入时间顺序,逐层安排。最新写入的在内存中,然后到达写缓存容量后,生成一个存储文件放置到L0层,当每一层的文件到达给层容量限制后,就会开启一个compaction工作:
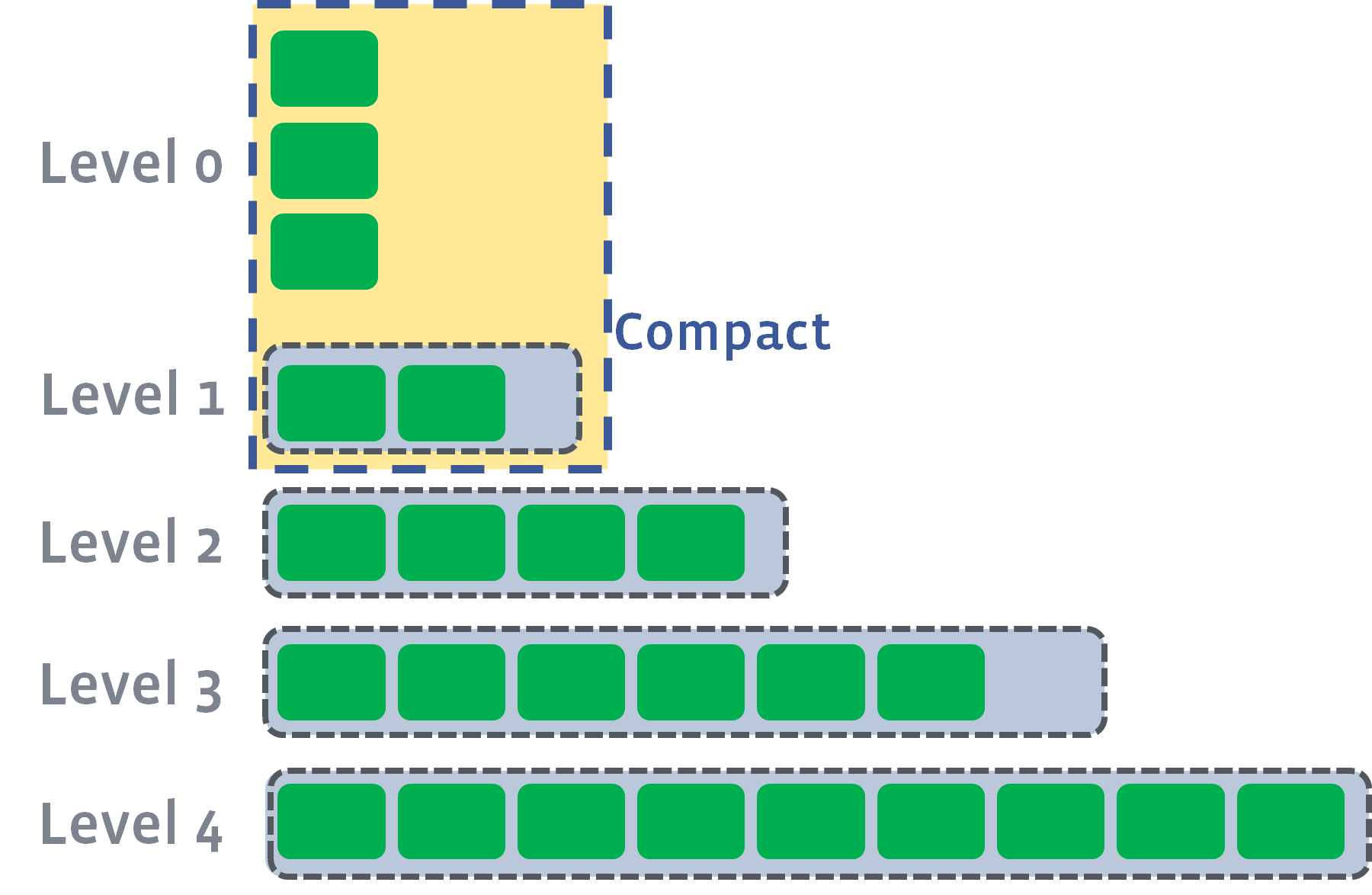
当L1的文件总大小超过该层限制后,会继续进行compaction工作,会挑选适当的文件合并入L2层:
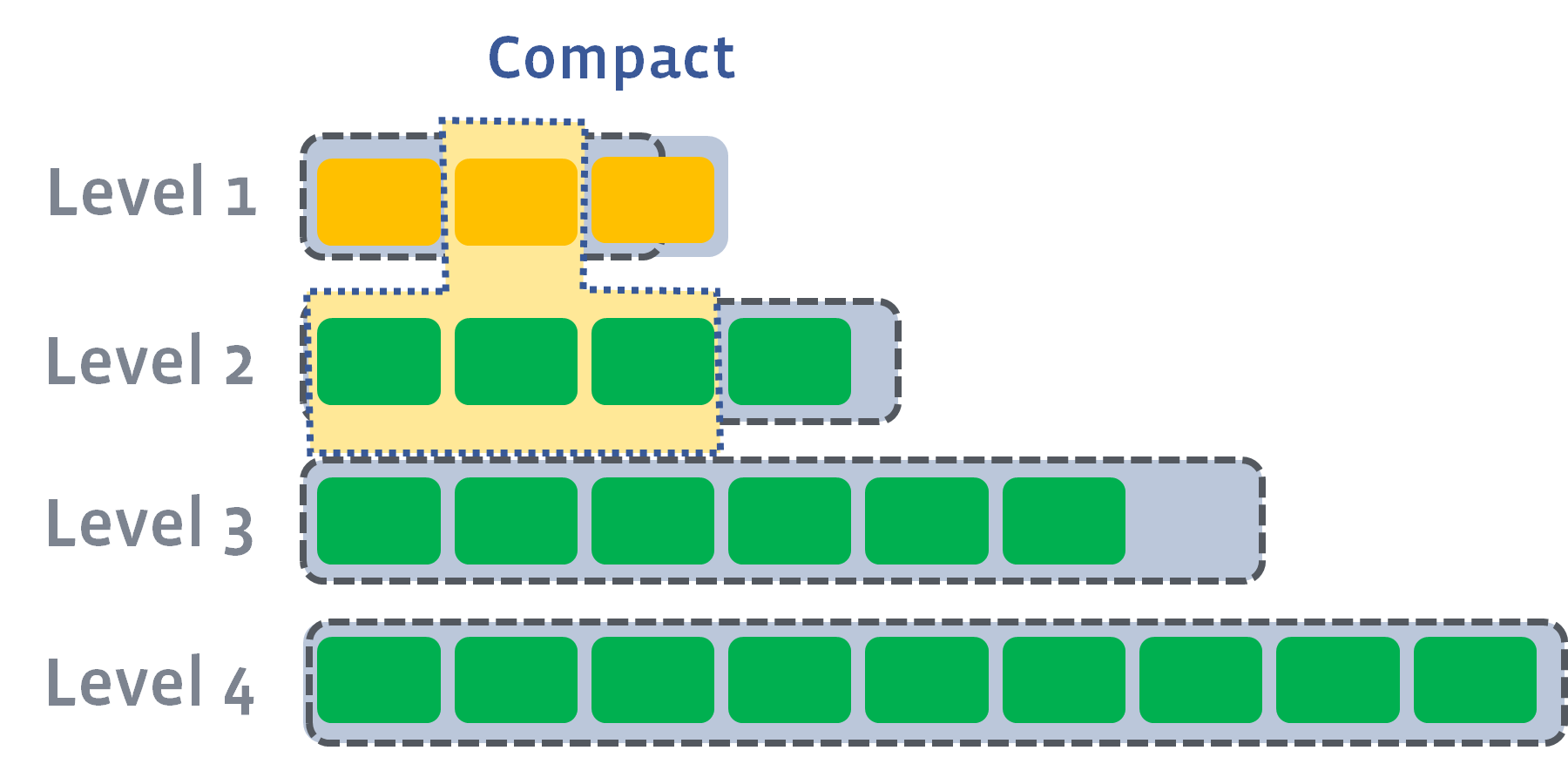
如果compaction后,使得L2层的总大小超过该层的限制,则继续向下compaction:
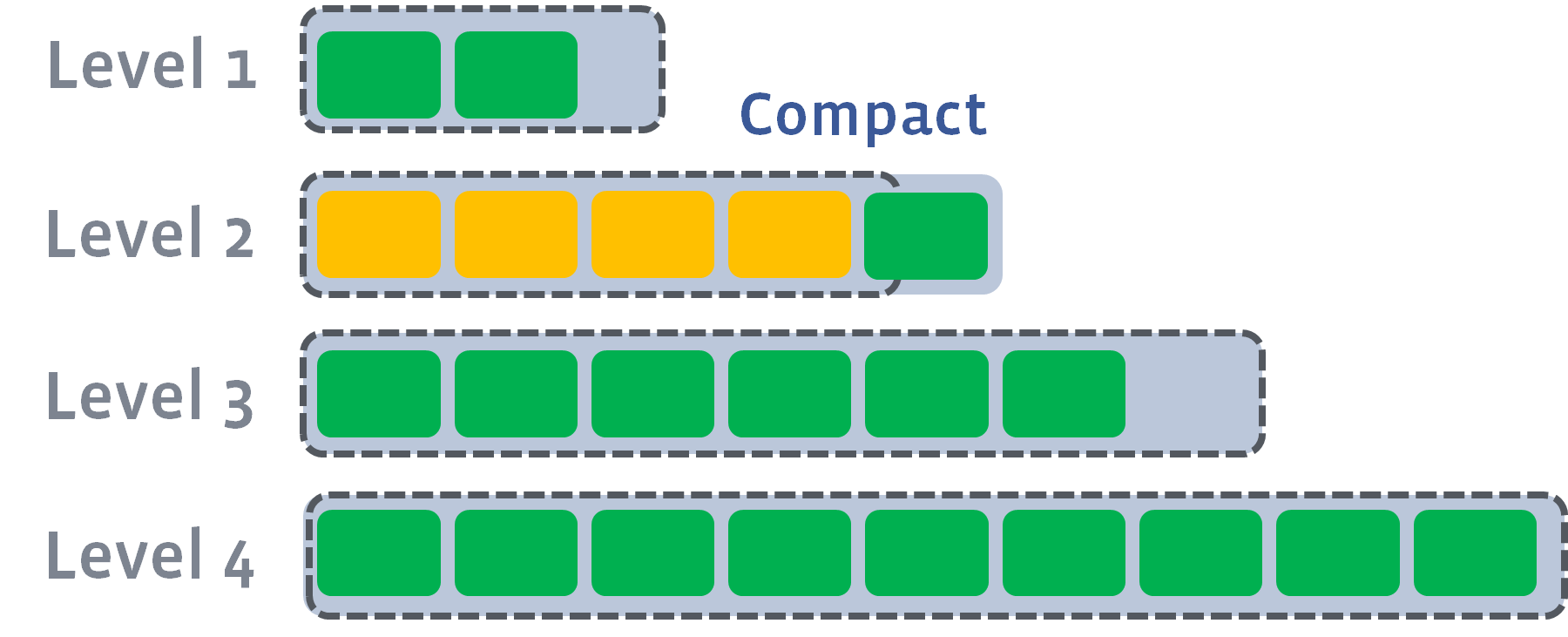
以此类推,最终将每层的文件大小控制在要求内。
那么我们就可以分析其中产生的空间放大:
首先,我们忽略WAL占用的额外空间,因为这个占用的磁盘空间大小是一个常数,通常这个值远小于磁盘容量,所以不太需要关注。
然后,然后分析每个场景的空间放大:
- 每层的数据都不重叠,很明显此时
空间放大为1 - 每层的数据都重叠,而且每层数据都填充慢,此时我们按照
增长系数 = 10,来计算,总数据容量为最后一层的大小,则空间放大为1.111... - 每层的数据都重叠,但是最后一层数据没有被填充慢,只略微比上一层大一点点,此时我们按照
增长系数 = 10,来计算,总数据容量为最后一层的大小,则空间放大为2.011...6
实验
在ScyllaDB3进行了两个实验,测试不同场景下leveled compaction的空间放大的实际表现
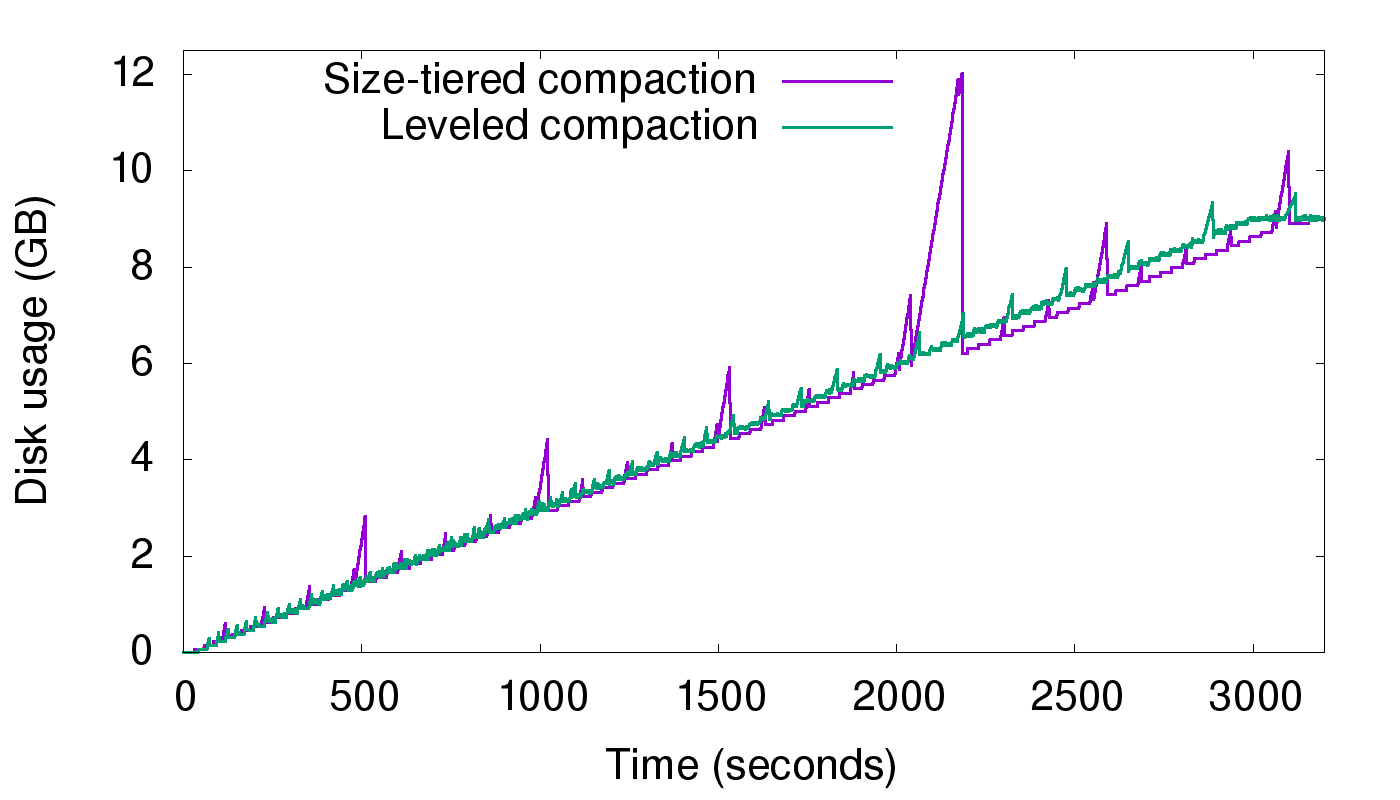
连续写入新KEY
在这个场景中,连续写入不重复的新KEY。可以看出,空间放大几乎为1。
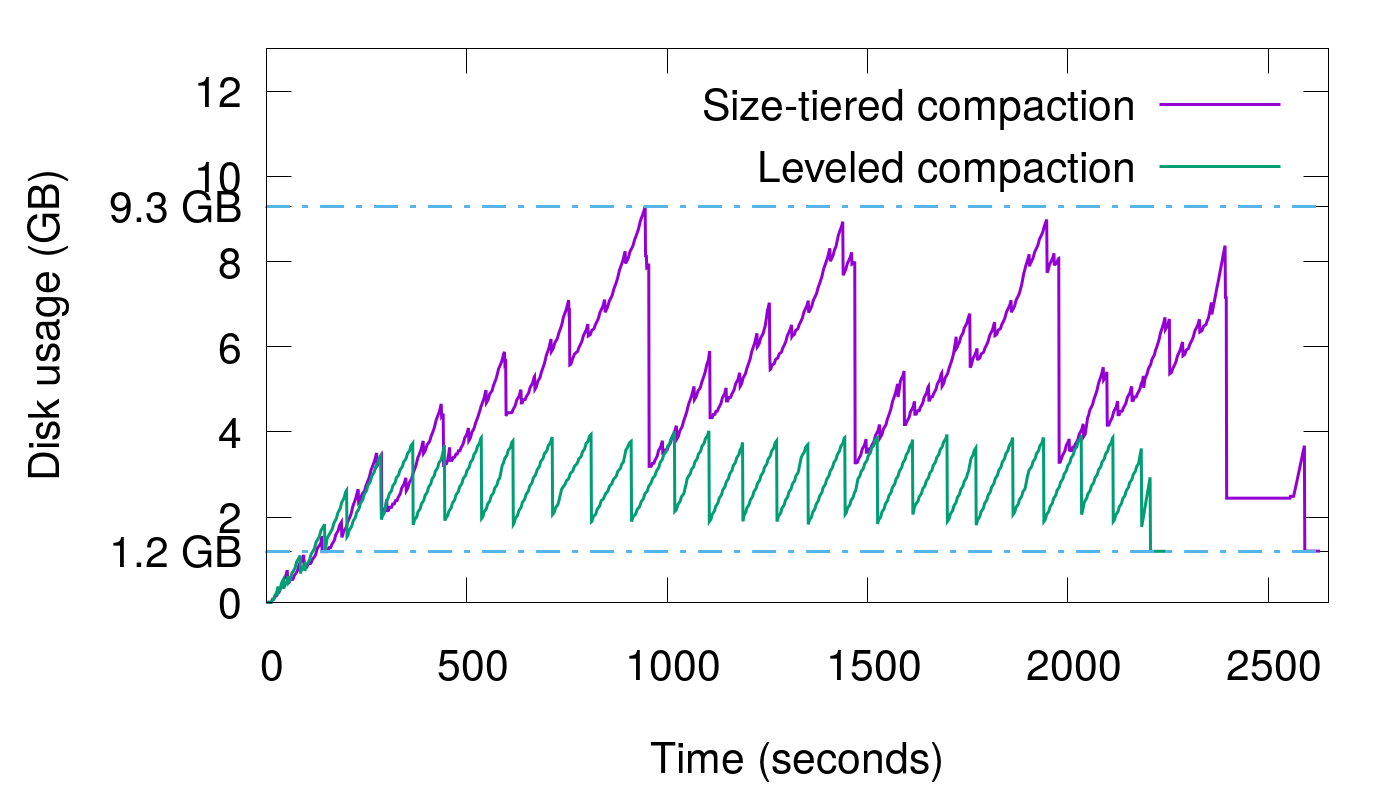
反复修改KEY
在这个场景中,反复修改1.2 GB数据,重复15次。可以看出,空间放大的范围为1.1-2。
附录
rocksdb目前支持4中compaction算法,在Options::compaction_style可以选择:
kCompactionStyleLevel,如上文所述。kCompactionStyleUniversal,本质上是tiered compaction算法,写放大比较低,但是读放大和空间放大比较高。kCompactionStyleFIFO,通常用于几乎不修改的场景,比如消息队列、时序数据库等。kCompactionStyleNone,关闭自动compaction,可以手动发起。
参考
注: 5中间讲了很多不同的compaction算法,中间会引用一个概念run/runs,在2中得到了这个概念的解释:
A run is a log-structured-merge (LSM) term for a large sorted file split into several smaller files. In other words, a run is a collection of sstables with non-overlapping token ranges.
文档信息
- 本文作者:Neal Hu
- 本文链接:https://lrita.github.io/2018/10/22/lsm-space-amplification/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)