体系架构
现在常见服务都是NUMA1架构,这种架构使得跨节点访问内存的代价大大增加,通常是访问本地内存的两到三倍以上:
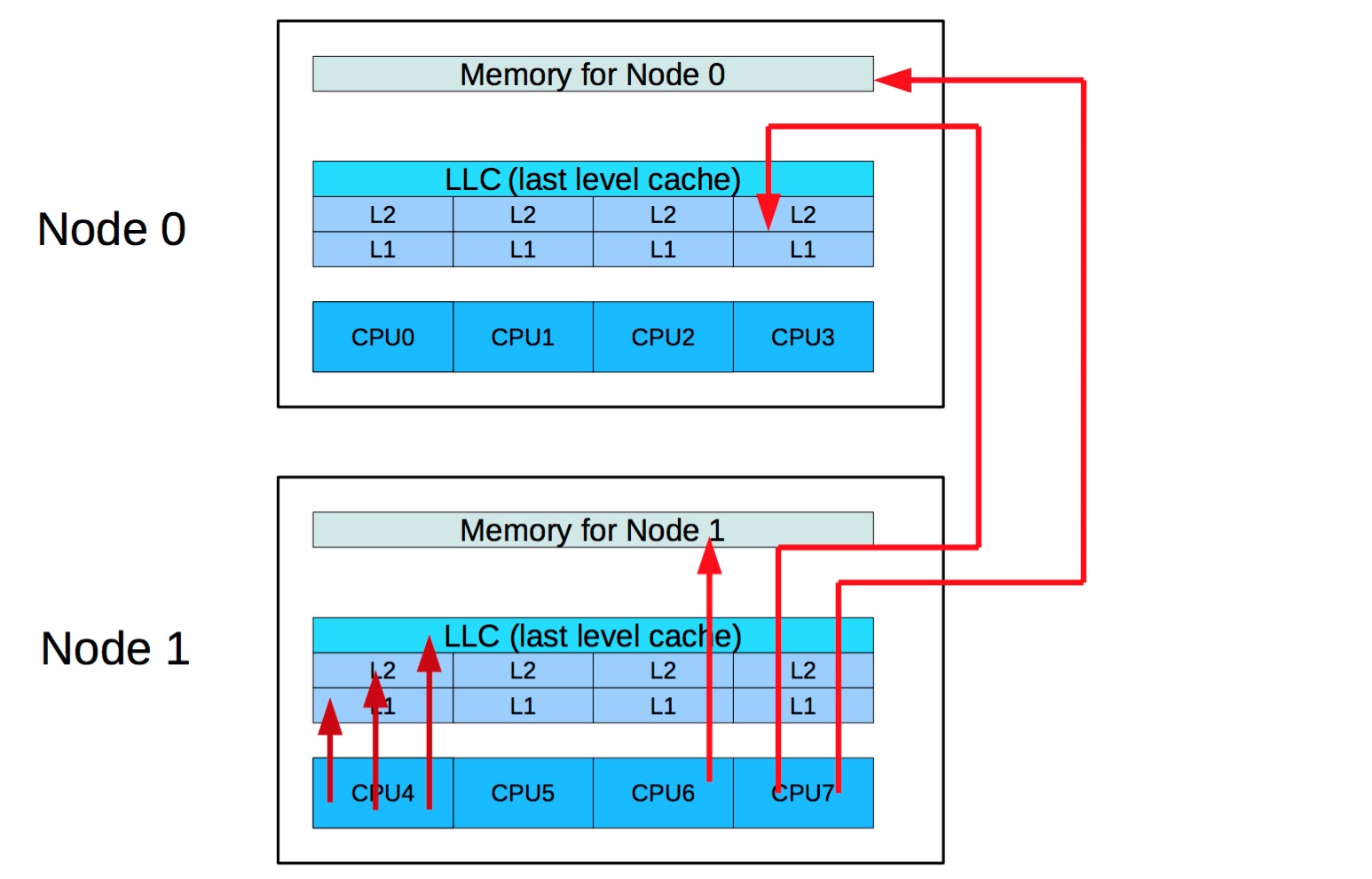
如果需要访问不相邻节点时,还需要通过其他节点的转发:
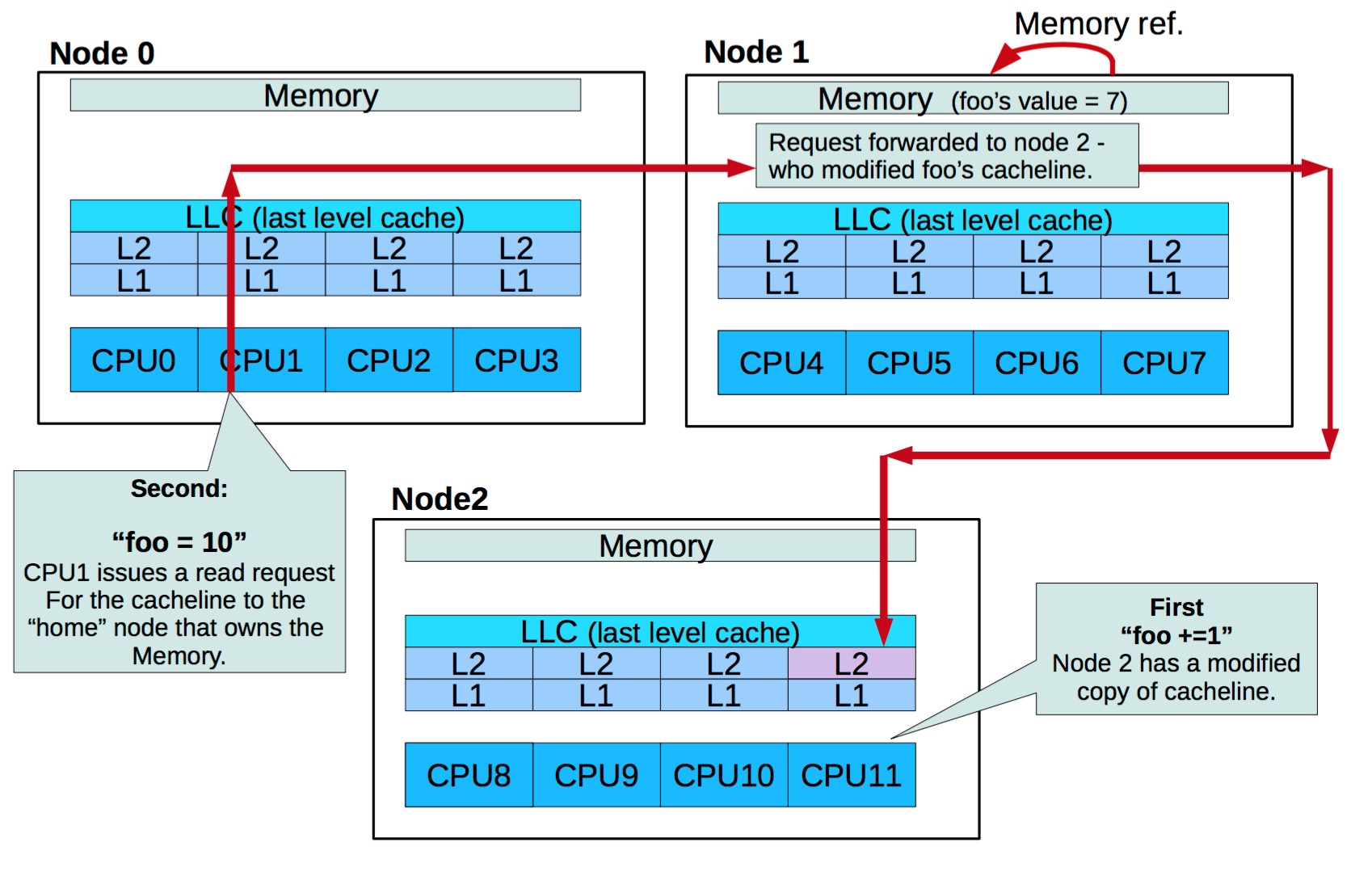
在这种架构中,CPU 的 cache 显得更为重要。那什么是 cache 的敌人?当然是使得cache失效的操作,在之前转载的文章《每个程序员都应该了解的内存知识-1》2中有详细讲到 cache 是如何工作的。
常见 cache 失效场景
常见的使得 cache 失效的场景有:
- 共享读写数据(自定义全局数据结构,锁等)
- 伪共享
共享读写数据很好理解,根据 cache 的一致性协议,改写一段内存会使得这段内存在其他 CPU 核心上对应的 cache 失效。那伪共享是什么?根据《每个程序员都应该了解的内存知识-1》2中讲到的,cache 的操作单位是 cacheline,x86-64 架构的 CPU 上是64字节,这样使得即使某些数据变量不被多个 CPU 核心共享,但是他们在内存上的布局过于接近,很可能处于同一个 cacheline 上,这样使得他们任一发生改变会使得另一者的 cache 也失效。
但是伪共享是十分隐蔽的,不如共享变量那样容易察觉。那如果我们的程序出现了性能瓶颈时,怎么判断是否是因为 cacheline 竞争导致的呢?
分析工具
我们可以使用perf c2c工具来诊断我们的程序是否存在 cacheline 竞争的问题。其最早出现在linux 4.9-rc2版本上,在RHEL 7.4的发行版中得到支持,CPU 需要Intel IVB以后的版本。
其使用起来也非常简单:
perf c2c record -g -u ./cache.test # 记录数据
perf c2c report -g --stats # 分析展示数据
C2C RECORD比较有用的参数有:
-l, --ldlat配置 mem-loads 延时,默认是30/P-k, --all-kernel配置是否记录内核空间发生的事件-u, --all-user配置是否记录全部用户空间的事件-g/--call-graph xx,xx配置启用调用链记录,记录的方式有fp(frame pointer)、dwarf(DWARF's CFI - Call Frame Information)和lbr(Hardware Last Branch Record facility),-g等同于--call-graph fp,8192,后面那个数字是栈dump大小,默认8192字节。
C2C REPORT比较有用的参数有:
-g, --call-graph--stats只打印统计信息
其他一些例子:
# system wide, latency, user space, callchains:
perf c2c record -u -l 50 -- -a -g sleep 10
# specific process, user space, callchains:
perf c2c record -u -- -p 1234 -g
# system wide, kernel space, latency/frequency:
perf c2c record -k -l 100 -- -F 80000 -a
# system wide, system wide, workload:
perf c2c record -- -a perf bench sched pipe
C2C的使用和分析
比如我们有一个程序是cache.test,那么我们记录该程序的 profile 数据:
perf c2c record -g -u ./cache.test # 记录数据
然后我们可以先看其统计汇总结果,结果的分析我们参考《Cache False Sharing Debug》3中一部分讲解:
perf c2c report -g --stats
=================================================
Trace Event Information
=================================================
Total records : 290513 >> 采样到的 CPU load 和 store 的样本总数
Locked Load/Store Operations : 12198 >> LOCK指令下的load/store操作数,Read-Modify-Write操作会使用到LOCK执行,比如atomic_add等
Load Operations : 75398
Loads - uncacheable : 0
Loads - IO : 0
Loads - Miss : 282
Loads - no mapping : 2
Load Fill Buffer Hit : 32203 >> Load 操作没有命中 L1 Cache,但命中了 L1 Cache 的 Fill Buffer 的次数
Load L1D hit : 33827 >> Load 操作命中 L1 Dcache 的次数
Load L2D hit : 3645 >> Load 操作命中 L2 Dcache 的次数
Load LLC hit : 3147 >> Load 操作命中最后一级 (LLC) Cache (通常 LLC 是 L3) 的次数
Load Local HITM : 133 >> Load 操作命中了本地 NUMA 节点的修改过的 Cache 的次数
Load Remote HITM : 1403 >> Load 操作命中了远程 NUMA 节点的修改过的 Cache 的次数
Load Remote HIT : 52 >> Load 操作命中了远程未修改的 Clean Cache 的次数
Load Local DRAM : 483 >> Load 操作命中了本地 NUMA 节点的内存的次数,其实这就是 Cache Miss
Load Remote DRAM : 1809 >> Load 操作命中了远程 NUMA 节点的内存的次数,其实这是比 Load Local DRAM 更严重的 Cache Miss
Load MESI State Exclusive : 2240 >> Load 操作命中 MESI 状态中,处于 Exclusive 状态的 Cache 的次数
Load MESI State Shared : 52 >> Load 操作命中 MESI 状态中,处于 Shared 状态的 Cache 的次数
Load LLC Misses : 3747 >> Load 操作产生的本地 NUMA 节点 LLC Cache Miss 的次数,是 Load Remote HITM,Load Remote HIT,Load Local DRAM,Load Remote DRAM 之和
LLC Misses to Local DRAM : 12.9% >> Load 操作产生的 LLC Cache Miss 中,从本地 NUMA 节点拿到内存的样本占 Load LLC Misses 总样本的百分比
LLC Misses to Remote DRAM : 48.3% >> Load 操作产生的 LLC Cache Miss 中,从远程 NUMA 节点拿到内存的样本占 Load LLC Misses 总样本的百分比
LLC Misses to Remote cache (HIT) : 1.4% >> Load 操作产生的 LLC Cache Miss 中,从远程 NUMA 节点拿到 Clean Cache 的样本占 Load LLC Misses 总样本的百分比
LLC Misses to Remote cache (HITM) : 37.4% >> Load 操作产生的 LLC Cache Miss 中,从远程 NUMA 节点拿到被修改过的 Cache 的样本占 Load LLC Misses 总样本的百分比,这是代价最高的伪共享
Store Operations : 215115
Store - uncacheable : 0
Store - no mapping : 0
Store L1D Hit : 214826 >> Store 操作命中 L1 Dcache 的次数
Store L1D Miss : 289 >> Store 操作命中 L1 Dcache Miss 的次数
No Page Map Rejects : 134
Unable to parse data source : 0
=================================================
Global Shared Cache Line Event Information
=================================================
Total Shared Cache Lines : 115
Load HITs on shared lines : 52541
Fill Buffer Hits on shared lines : 31867
L1D hits on shared lines : 11791
L2D hits on shared lines : 3438
LLC hits on shared lines : 2876
Locked Access on shared lines : 12181
Store HITs on shared lines : 14235
Store L1D hits on shared lines : 14144
Total Merged records : 15771
=================================================
c2c details
=================================================
Events : cpu/mem-loads,ldlat=30/P
: cpu/mem-stores/P
Cachelines sort on : Total HITMs
Cacheline data grouping : offset,pid,iaddr

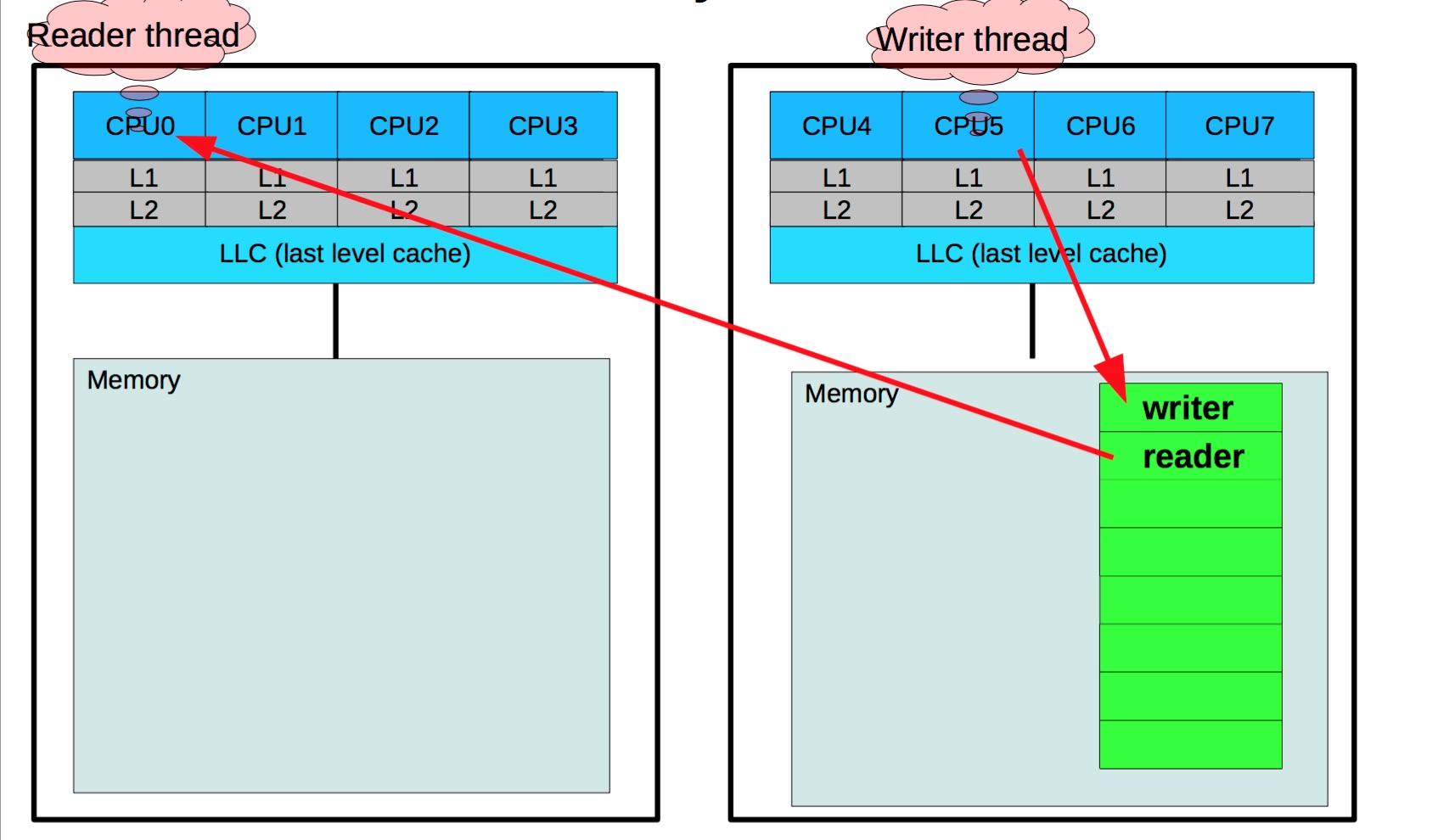
在perf c2c输出里,HITM意为Hit In The Modified,代表 CPU 在 load 操作命中了一条标记为Modified状态的 cacheline。如前所述,伪共享发生的关键就在于此。而Remote HITM,意思是跨 NUMA 节点的 HITM,这个是所有 load 操作里代价最高的情况,尤其在读者和写者非常多的情况下,这个代价会变得非常的高3,图解这两个行为就是:
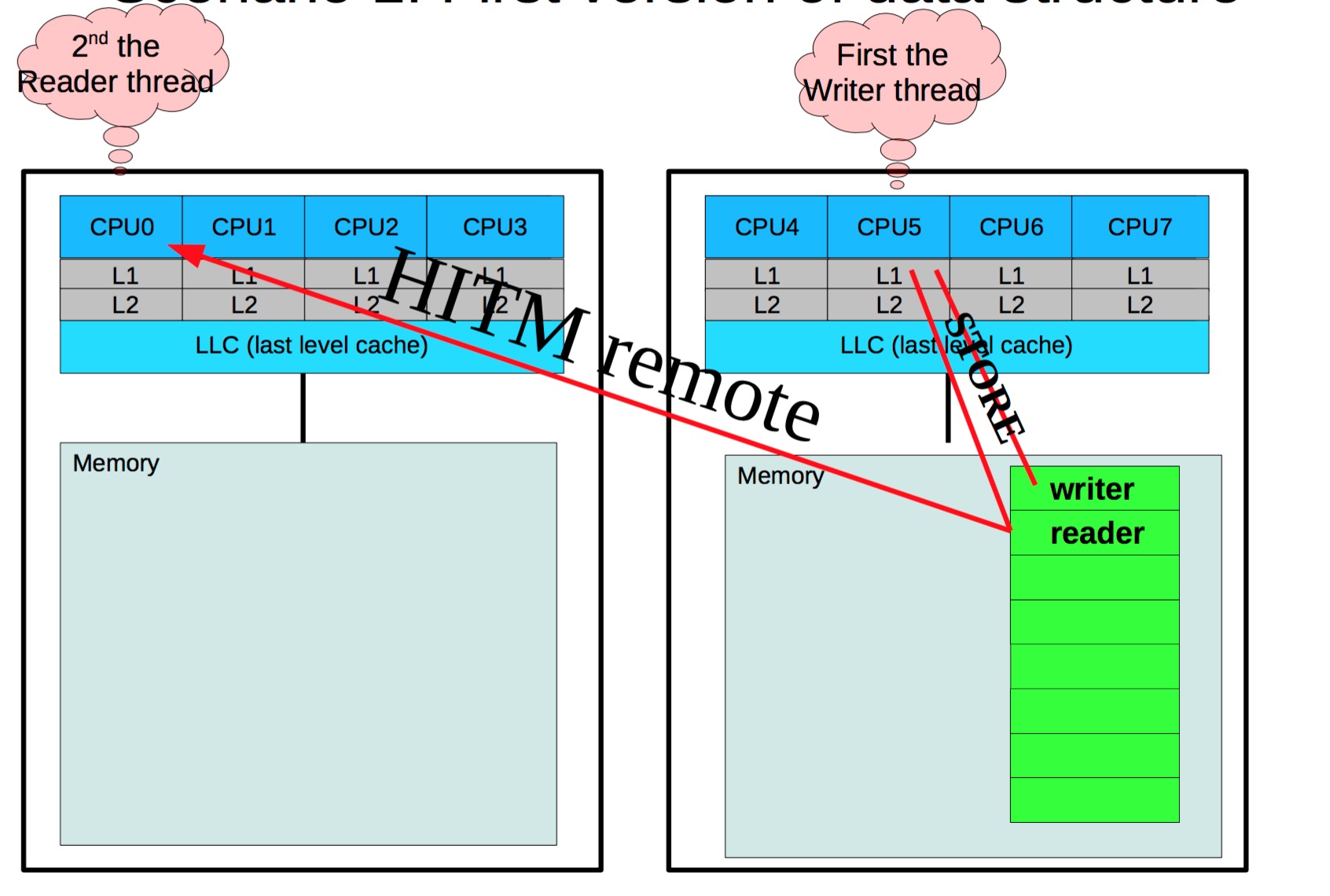
在这个统计输出中,我们通常观察一下Load LLC Misses、Store L1D Miss、LLC Misses to Remote cache (HITM)是否过高,至于这几个数据多高才算有问题,得根据实际经验来分析,没有硬性指标。尤其是LLC Misses to Remote cache (HITM)的数字。只要不是接近 0,就可能有值得追究的伪共享。
其次,我们可以使用以下命令来查看更加详细的 cacheline 竞争的报告,其默认按照发生Remote HITM的次数比例排序,添加参数-d lcl按照发生Local HITM的次数比例排序:
perf c2c report -g
执行该命令后,会进入一个TUI界面,其中展示的数据比较多,通常一个屏幕显示不全,可以通过光标键”←”/”→”来调整:
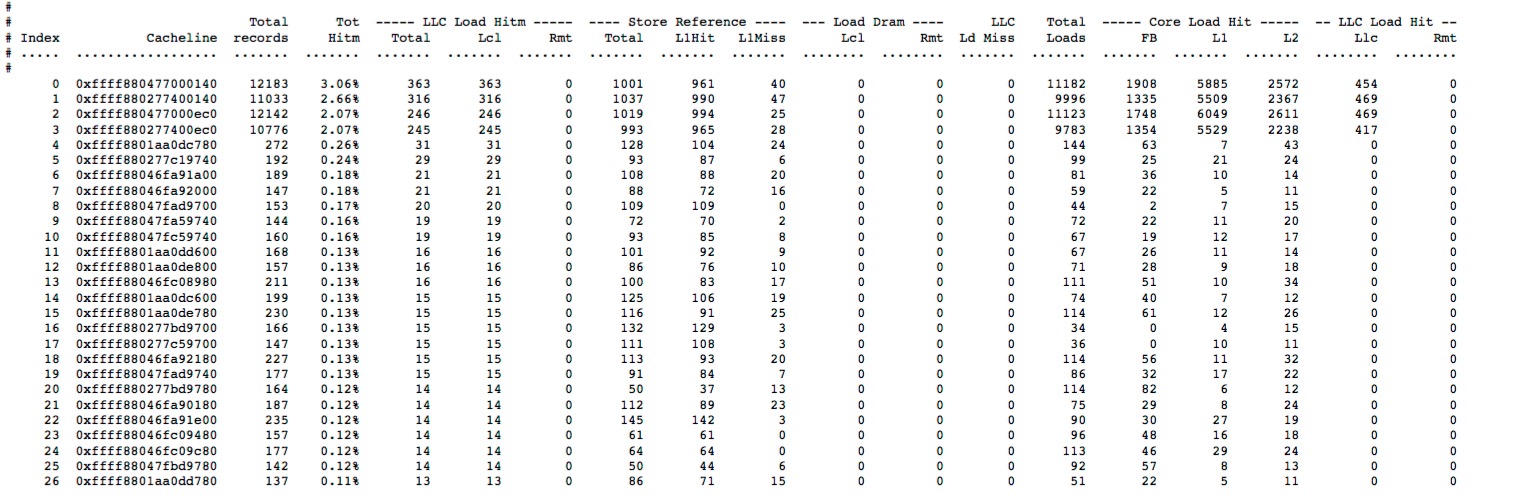
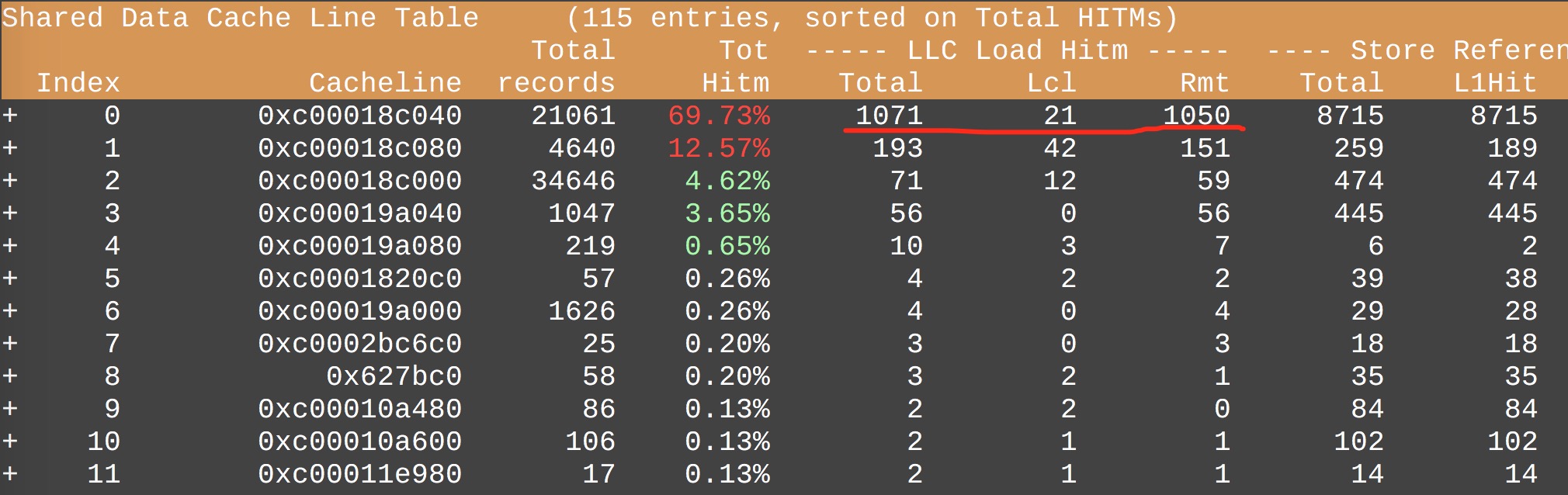
在上图中的数据是前面汇总统计的细节版,每一行代表一个 cacheline,然后按照Remote HITM的降序排列,同时会显示一个HITM比例,这个比例是指该 cacheline 发生的HITM占全部的HITM百分比。正常情况下HITM应该是均匀分布的,如果出现其中几条 cacheline 发生的HITM占比过高,则说明在这几条 cacheline 上发生了激烈的竞争。比如下图中,cacheline 0xc00018c040 发生的HITM总次数为1071,本地次数21,远程次数1050,第一条命令输出的汇总信息中Load Local HITM和Load Remote HITM总和为1536次,占比69.7%。这就说明,多个CPU核心在这个 cacheline 上发生激烈竞争。
然后我们还可以通过光标键”↑”/”↓”来选中对应的 cacheline,然后按快捷键d,进入到该条 cacheline 的Pareto百分比分布表,命名取自帕累托法则 (Pareto principle),显示了每条内部产生竞争的 cacheline 的百分比分布的细目信息。每一行代表一个访问该 cacheline 的代码,包含访问该 cacheline 对应的代码符号、代码行数等,由于信息宽度比较大,可以通过光标键”←”/”→”来调整:


在该表中,可以移动光标键”↑”/”↓”来选中对应的代码,按ENTER键,会展示具体的函数调用栈信息:
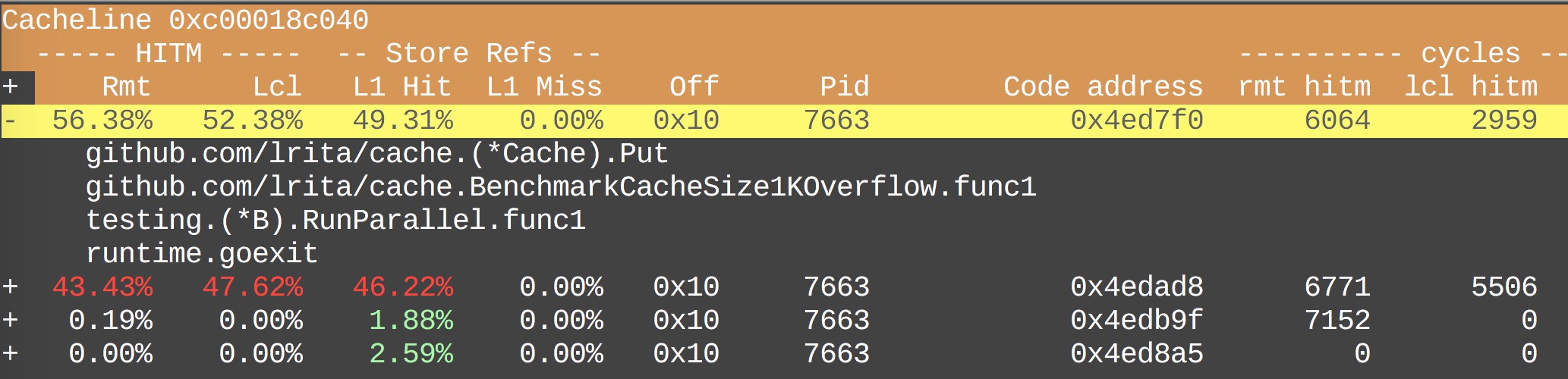
我们可以很清楚地看到该 cacheline 都会被哪些代码访问的,他们之间竞争的占比是多少,大大提高了定位代码的速度。
扩展
- 如何增加采样频率
perf record 增加参数-F 60000 或者 -F 80000,而系统默认的采样频率是 1000。
提升采样频率,可以短时间获得更丰富,更可靠的采样集合。想提升采样频率,可以用下面的方法。
可以根据 dmesg 里有没有 "perf interrupt took too long …" 信息来调整频率。注意,如前所述,
这有一定风险,严禁在线上或者生产环境使用。
# echo 500 > /proc/sys/kernel/perf_cpu_time_max_percent
# echo 100000 > /proc/sys/kernel/perf_event_max_sample_rate
然后运行前面讲的 perf c2c record 命令。之后再运行,
# echo 50 > /proc/sys/kernel/perf_cpu_time_max_percent
- 如何让避免采样数据过量
如果我们采集到数据中HITM很多,以至于我们无法分辨出什么,或者采集到的数据过多,无法分析。则我们可以
提高采用点的阈值:
使用“-ldlat 50”将采用的延时阈值从30 cycles 增加大到 50 cycles。
- 采样时间不宜过长
perf c2c 采样时间不宜过长。Joe 建议运行 perf c2c 3 秒、5 秒或 10 秒。运行更久,观测到的可能就
不是并发的伪共享,而是时间错开的 cacheline 访问。
-u/-k诊断问题发生在用户空间还是内核态
由于perf c2c每次只能采集一个空间的cacheline信息,则遇到问题时,需要分别通过修改参数`-u`/`-k`诊断
问题发生在用户空间还是内核态。
优化代码4
当我们发现 cacheline 竞争后,应该如何优化代码呢?
首先要根据业务逻辑需求来进行判断,比如业务要求一个任务要全局有序,则需要一把全局锁,那在这把锁上的 cacheline 竞争就很难有优化的余地。
如果存在优化的空间,我们具体的思路就是:
- 将(几乎)只读数据放置在一起
将它们放置在一起,使得我们分别访问它们时,需要更少的cacheline,而且这部分数据几乎不会被修改,没有竞争的代价。
- 分清代码的冷热路径
分清代码中的冷热路径,集中优化热路径中的代码。比如通常代码中需要很多统计点、计数器,关于这些点,写操作明显是热路径,会被经常改写,而读操作一般是冷路径,通常每秒/每分钟才输出一次统计结果。这样我们就可以偏向热路径进行优化。比如我们可以给每个线程分配一个计数器,每个协程单独修改自己持有的计数器,统计结果时,遍历每个线程独享的计数器进行汇总。这样在热路径中会产生最少的 cacheline 竞争。
- 把数据结构对齐到 cacheline,并填充其结构使其大小为 cacheline 整数倍以减少伪共享
- 减少锁竞争
分析逻辑,看能不能拆分锁的粒度,使得全部线程不要都去竞争同一把锁,比较常见的例子就是
concurrent-hash-map的实现。
参考
文档信息
- 本文作者:Neal Hu
- 本文链接:https://lrita.github.io/2018/11/20/debug-cpu-cacheline-false-sharing/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)