现在多核计算机已经成为了当今主流,因此我们在每个程序中都需要考虑到多核并发的问题,在有高性能计算需求的项目中更是重要。其中在数据结构中,我们需要对并发考虑的更多,这里就要涉及很多并发算法。
在高并发的场景下,经常需要一些非常高效、并发度高的数据结构。通常基于悲观并发会加入互斥锁、信号量等同步原语。这样是一种阻塞算法,当持有互斥锁的线程被挂起后,其他线程也会被阻塞住,是一种并发度比较低的算法。与之相比并发度更高的有一些非阻塞算法。总之,互斥原语存在很多缺点1。但是使用互斥语义在代码上实现简单,适用于大多数场景。
下面我们就要介绍一些并发度更高的非阻塞算法模型,这里我们并不叙述某一具体类型算法的实现,而是将它们之间的分类、区别,主要从概念上出发,这样可以让我们接触到一些具体实现时,可以通过其实现的关键点将其迅速归类,从而分析出该实现的原理性边界。
基本概念
阻塞(block)
阻塞(block)这个概念是我们讨论下面问题的基石,其定义是:
A function is said to be Blocked if it is unable to progress in its execution until some other thread releases a resource.
我认为同时具有以下两点特征的都是阻塞(block)的:
- 互斥性(串行操作)
比如超市的结账通道,大家只能按照一定的顺序依次结账。牌堆同时有很多张扑克,荷官依次给每一名玩家发牌,而不是大家同时去牌堆抢牌。又如
mutex保护一个变量,将所有修改变量的操作依次执行。 - 通过性(故障容忍)
比如超市的结账通道,如果正在结账的顾客与收银员发生了冲突,则后面的顾客也只能等待。如果此时没有任何机制接入,则是不能容忍故障的一种表现。如果此时有经理介入,将该名顾客请离结账通道单独处理,这样收银员就能继续服务其他顾客。又如持有
mutex的线程如果发生的异常,没有释放mutex,则关于该mutex的全部操作都无法进行处理。这里要特别指出一点,
阻塞(block)是指处理一件事的全部过程,从头到尾的这个过程。还是上面那个例子,如果一个顾客与收银员正在发生冲突,后面等待的顾客比较聪明,他们离开了结账通道,再去做些其他事,比如上洗手间,待会再来查看结账通道是否恢复。这样整个过程仍然是阻塞(block)的,因为在这个过程中后续顾客仍然是没有完成结账这个目的,只不过是中间穿插进行了一些其他无关事件。因此mutex中的trylock仍然是阻塞(block)的,trylock只是可以帮助线程在被阻塞时能进行一些无关工作,如果一直trylock失败,则其目一直无法达成。在知乎上一些人认为trylock是wait-free的,这是极大的认知错误。
比较简单的例子,通过CAS循环来同步状态。
AtomicInteger lock = new AtomicInteger(0);
public void funcBlocking() {
while (!lock.compareAndSet(0, 1)) {
Thread.yield();
}
}
步进性(progress)
步进性(progress),对这个翻译也不是太满意,后面都使用progress。progress是一个指标,用来衡量一个算法“非阻塞”的程度,因此阻塞(block)算法的progress最低。如果每个参与者的操作都能在有限时间内完成,这样的progress是最高的,意味着每个参与者都不会被阻塞(block)。
需要明确的一点是,progress高并不一定代表效率高。在一些场景下阻塞的实现可能比非阻塞的实现效率更高,比如一个算法,如果采用阻塞的实现,每个线程只需要10ms,但是采用非阻塞的实现可能就需要100ms。
讨论范畴
在讨论这些问题前,首要的是,我们明确我们讨论的范畴,通常会有很多人没有明确讨论的范畴导致将一些概念混淆在一起。在常规情形下,我们讨论这类问题从小到大分为:
- 数据结构,判断是否阻塞的范畴是线程,我们讨论的是线程操作的
progress。 - 数据库事务,判断是否阻塞的范畴是事务,我们讨论的是事务操作的
progress。 - 分布式编程,判断是否阻塞的范畴是进程,我们讨论的是进程操作的
progress。
下面的讨论以数据结构的范畴为准,要扩展到其他范畴,需要做针对性的变化。
算法分类
通常情况下,将各种并发算法可以分为以下几类,通常一个数据结构的不同方法可能采用不同的算法实现。比如一个map结构,读方法可能是lock-free的而写方法是deadlock-free的。
deadlock-free
deadlock-free是一个并发数据结构的最低要求,其实现不会产生循环依赖的资源。因为循环依赖的资源会造成死锁情况的发生。
starvation-free
starvation-free有时也被叫做lockout-free,通常取决于系统底层的保证。其定义为:想进入临界区的线程最终也够进入。
通常一个完全公平调度的排他锁是starvation-free的,比如x86中依赖内存总线锁实现的操作atomic_fetch_add()。比如完全公平锁Ticket Lock等实现。
obstruction-free
obstruction-free是最弱的非阻塞progress保证,其要求:在任何一线程单独运行时(其他线程都休眠或等待时),它能够在有限步数内完成相关操作。所有的lock-free算法都是obstruction-free的。
obstruction-free通常只要求任何部分完成(未全部完成)的操作可以被中断且回滚。可以阻止系统在争抢资源时,进入live-locking状态。
一些obstruction-free算法在实现时引入”consistency markers”角色,在一些操作前后都读取”consistency markers”的状态进行比较,当”consistency markers”指示状态发生变化时,其进行回滚重试。
类似的实现有:《Obstruction-Free Synchronization: Double-Ended Queues as an Example》2。
lock-free
lock-free对部分线程提供progress保证,其可能造成部分线程处于饥饿状态,但是在整体上提供了较大的吞吐。其定义是:
当程序的全部线程运行的时间足够长时,至少有一个线程能确保完成操作,保证
progress(能够容忍任意线程被挂起,简单来说,就是前面提到的通过性,整个算法不会受到某一线程故障的影响)。
则,有任意两个线程争抢同一mutex或spinlock的算法,都不是lock-free的。所有的wait-free算法都是lock-free的。
In general, a lock-free algorithm can run in four phases: completing one’s own operation, assisting an obstructing operation, aborting an obstructing operation, and waiting. Completing one’s own operation is complicated by the possibility of concurrent assistance and abortion, but is invariably the fastest path to completion.3
如何正确的处理when to assist, abort or wait是非常复杂的,而且可能带来非常高的性能损耗,但是好歹还是保证了progress。
比如,用CAS循环来实现一个原子自增逻辑:
AtomicInteger atomicVar = new AtomicInteger(0);
public void funcLockFree() {
int localVar = atomicVar.get();
while (!atomicVar.compareAndSet(localVar, localVar+1)) {
localVar = atomicVar.get();
}
}
wait-free
wait-free是最强的progress保证,同时结合了最大的系统吞吐和避免饥饿。其保证所有参与操作的线程能在有限步数内完成,通常这个有限步数与参与的线程数有关。
理论上,所有的算法都可以被设计为wait-free的,但是不能保证其效率高于block的实现4。
例如:《Wait-Freedom vs. Bounded Wait-Freedom in Public Data Structures》5
关联关系
虽然人们都把相关算法分为这五大类,但是他们之间分隔的维度并不统一,他们之间并不是简单的包涵、从属关系。下图可以简单的表示他们之间的属性关系,箭头指向的方向是算法具备的属性。例如wait-free同时具备lock-free和starvation-free属性6。
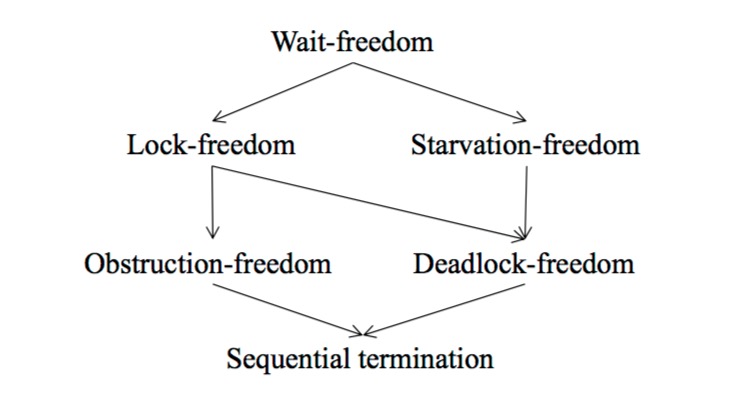
上图从中间分开,他们从不同方面定义了算法的属性。具备wait-free、lock-free或obstruction-free属性的可以被称为非阻塞的算法,他们从“保证参与者最终能完成操作”出发,区别在于保证的参与者数量和参与者之间是否需要协调。而具备deadlock-free或starvation-free不一定是非阻塞的。deadlock-free或starvation-free从参与者的公平性上出发,区分不同算法。
还有一种“大统一理论”7的划分方式,将这些算法划分为二维区间:
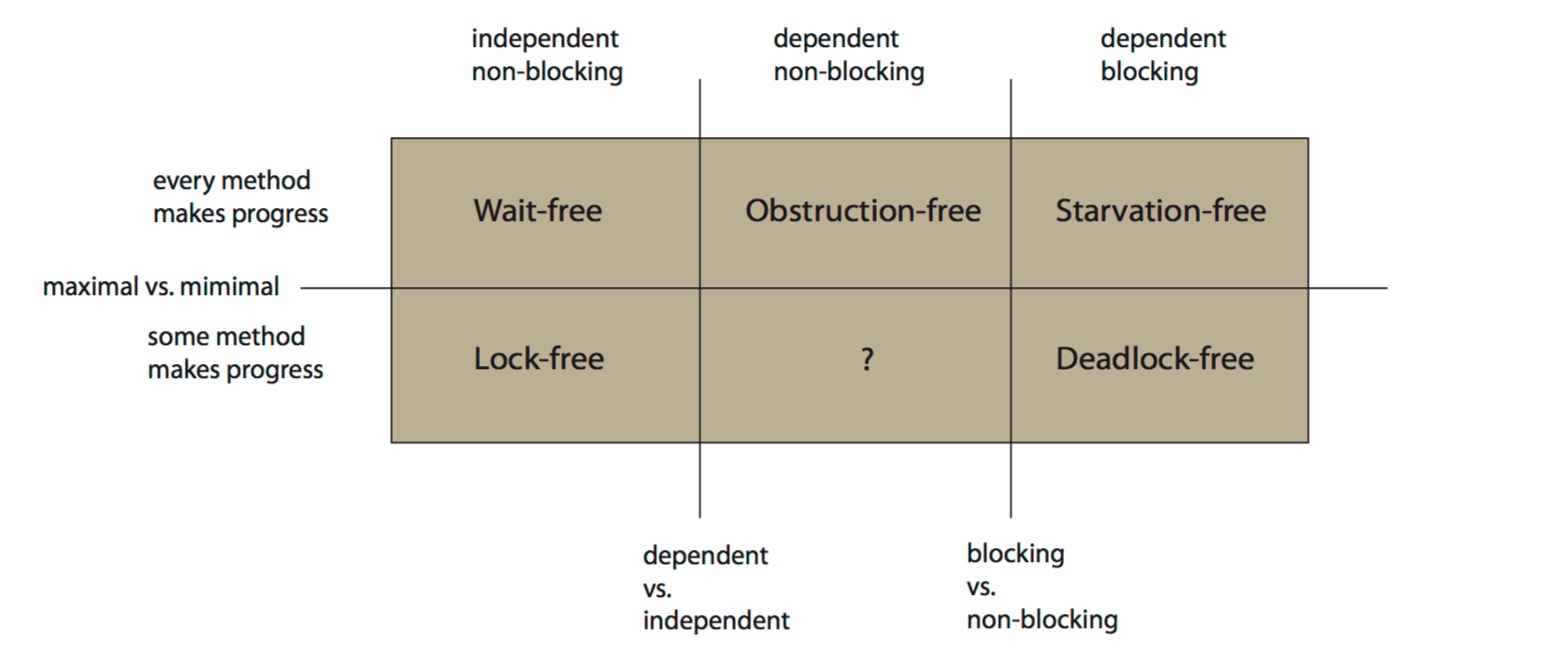
在上图中,Y轴的维度是progress,上侧的算法比下侧的具有更高的progress。而X轴方向的维度则不是唯一的,首先偏左的垂直线将X轴分为2部分,其分割的依据是是否依赖系统对线程的调度,左侧不依赖系统调度,而右侧依赖系统调度;偏右的垂直分割线的依据是是否阻塞,线左侧是非阻塞,线右侧是阻塞的(这里不太同意这种归类,我认为starvation-free只是一种依赖调度属性,与是否阻塞不是一个维度)。
参考
文档信息
- 本文作者:Neal Hu
- 本文链接:https://lrita.github.io/2019/02/05/non-block-algorithm-with-concurrence/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)