分层结构
Linux 文件系统采用分层设计,不同层抽象出来完成不同层次的逻辑。其中的复杂的设计,可以拿两张图在不同程度上描绘:
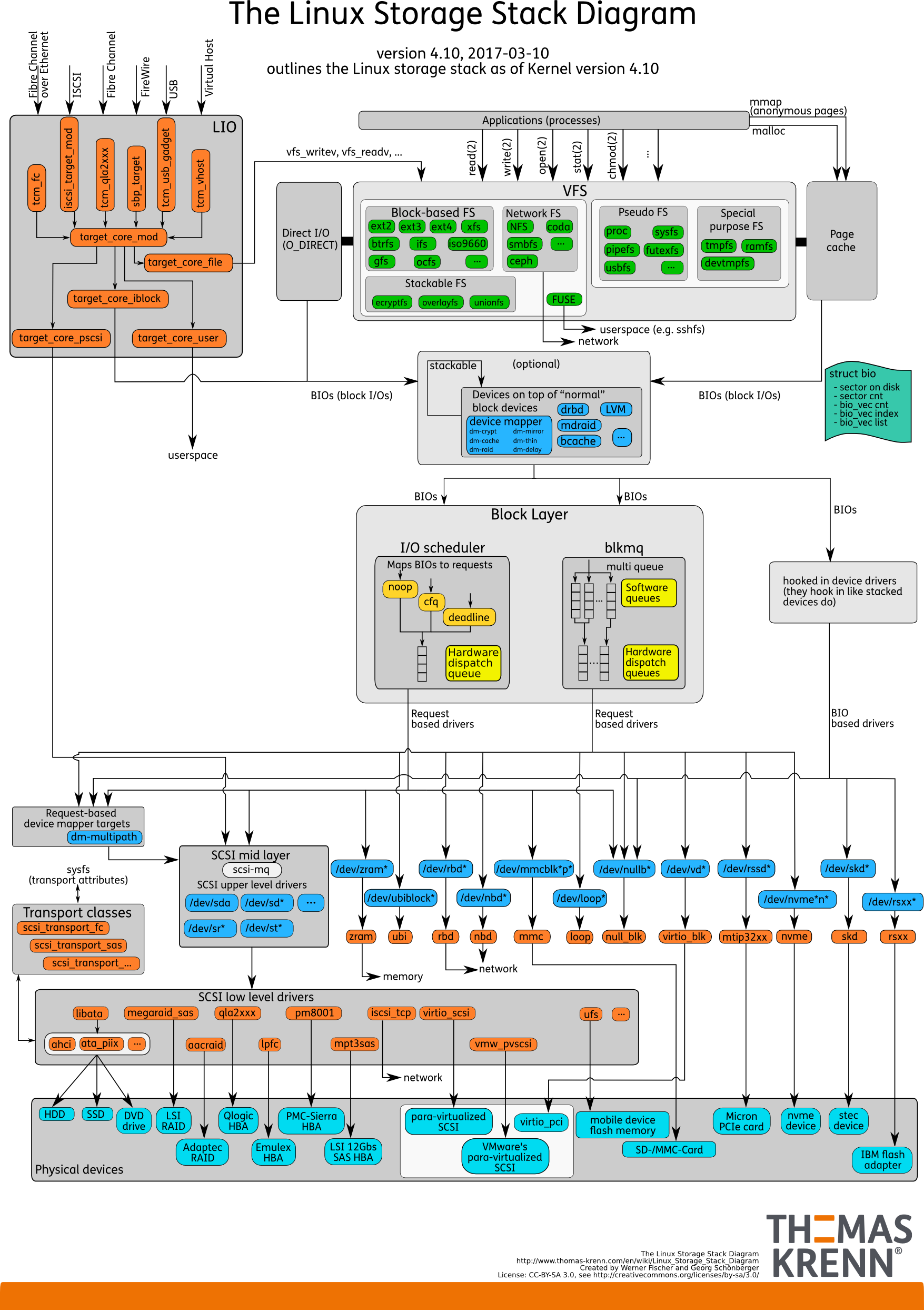
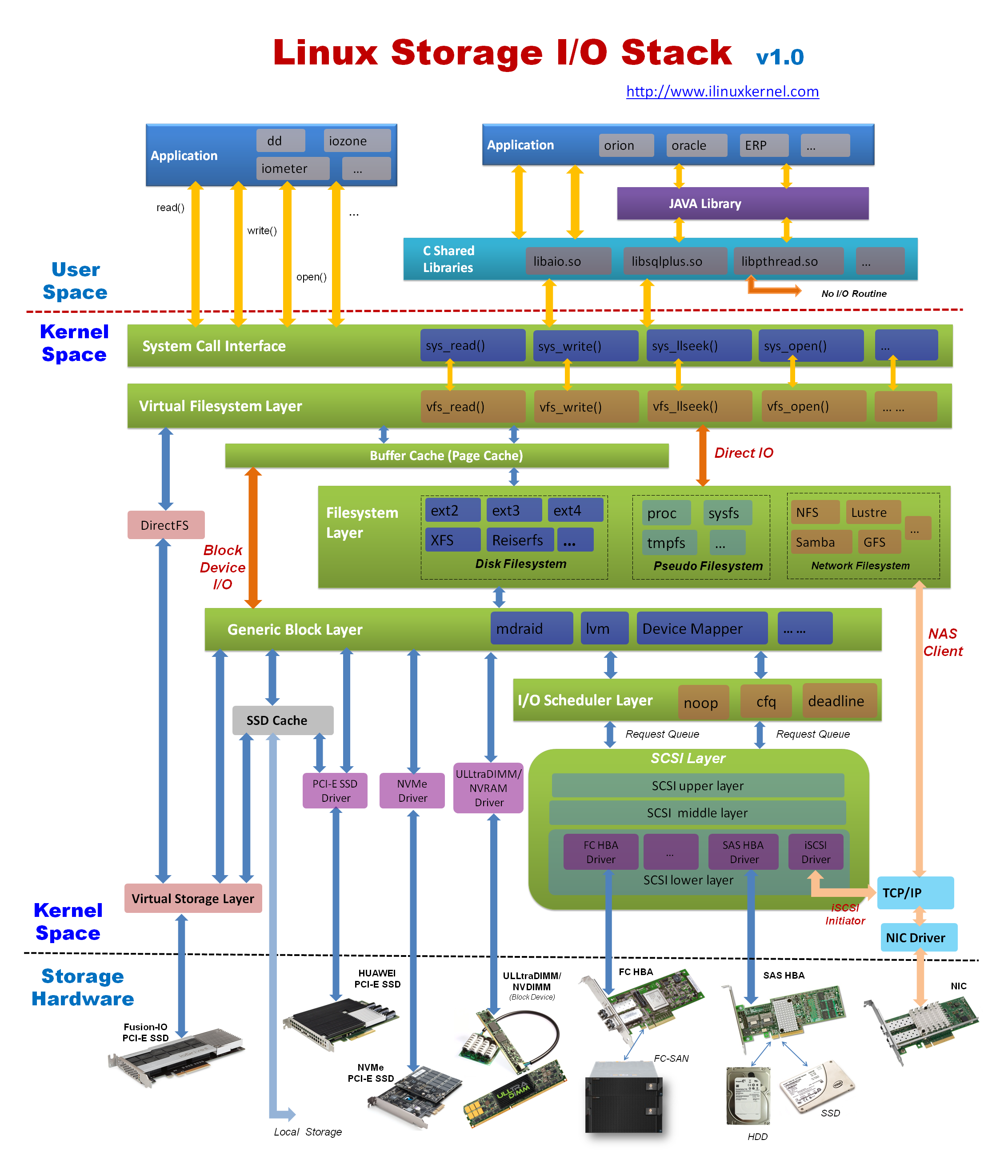
因此用户态的应用程序每一个 IO 请求产生的数据都会经过文件系统的不同抽象层,但是很多抽象层之间是异步交互的,这使我们理解文件系统的难度又进一步提升。当然,还可以用一个简单的抽象来表示其中每个抽象层之间的关系:
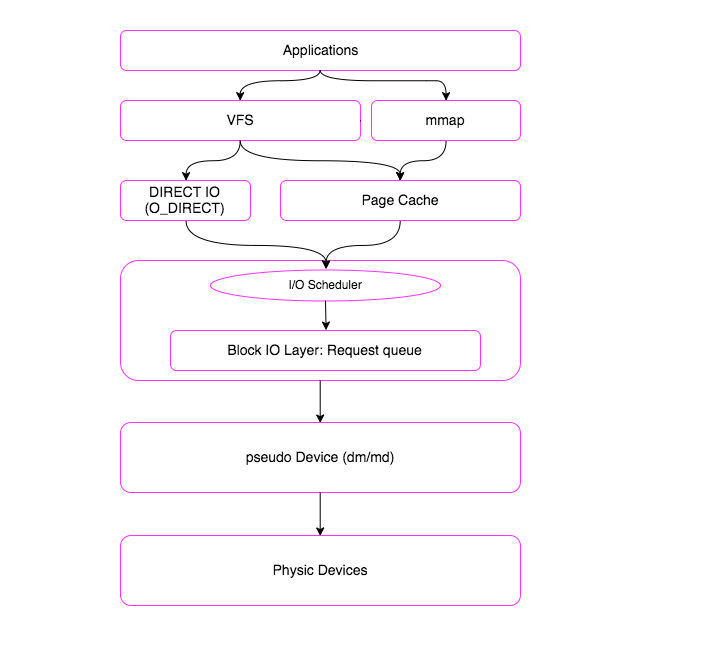
下面我们会简单分析一些场景文件 IO 系统调用的内核流程,让我们了解其中的内幕。
虚拟文件系统
为了连接不同文件系统的设计,内核在各种文件系统之上增加一个抽象层虚拟文件系统(VFS),很多通用设计都在其中,包括一个文件在内核中如何表示、元数据struct file、struct inode等的,具体分析可以参考:《Linux 虚拟文件系统》
每个文件open后,会得到一个struct file来,在用户进程中为一个int fd来表示,文件读写偏移等元数据存储在struct file中。
同时,每个文件有唯一的一个struct inode,文件权限、属性等存储在其中。
因此,多个struct file可以对应同一个struct inode。
pagecache
pagecache是内核为文件创建的内存缓存,用以加速相关的文件操作。当应用程序需要读取文件中的数据时,操作系统先分配一些内存,将数据从存储设备读入到这些内存中,然后再将数据分发给应用程序;当需要往文件中写数据时,操作系统先分配内存接收用户数据,然后再将数据从内存写到磁盘上。
pagecache的内存在内核中是匿名的物理页(不与用户进程的逻辑地址进行映射),由struct page表示,在内核中pagecache使用 LRU 管理,当用户进行mmap映射文件时,内核创建对应的vma,在访问到mmap的内存区域时,触发page fault,在page fault回调中pagecache内存所属的物理页与用户进程的虚拟地址vma进行映射。- 每个文件的
pagecache元数据存储于对应的struct inode->address_space中,因此进程之间可以共享同一个文件的pagecache,同一个文件多次open不会影响其pagecache。 - 文件的
pagecache是延时分配的,当有读写命令时,才会按需创建缓存页。 pagecache的脏页是单线程回写的,因此当一个文件大量写入时,写入的性能与单 CPU 的性能有相当的关系。
详细的分析可以参见:《Linux 内核文件 Cache 机制》、《Linux 内核延迟写机制》
块设备层
块设备层在不同版本中有不同的划分方式,但是总的来说可以分为《Linux 通用块设备层》和《Linux 内核 IO 调度层》。其中两部分可以详见链接中的讲解。
关于块设备层中的主要逻辑流程,可以参考下图:
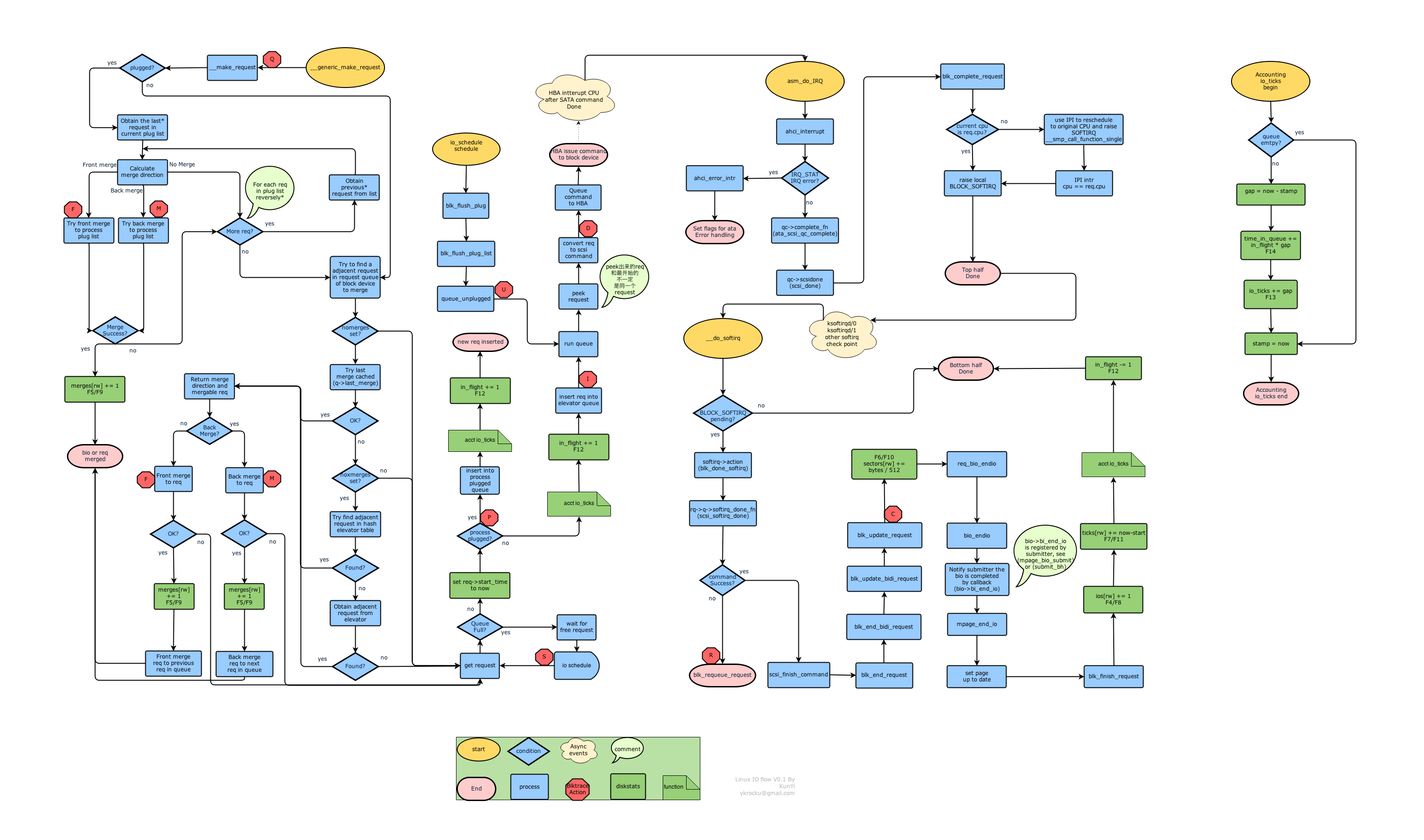
系统调用
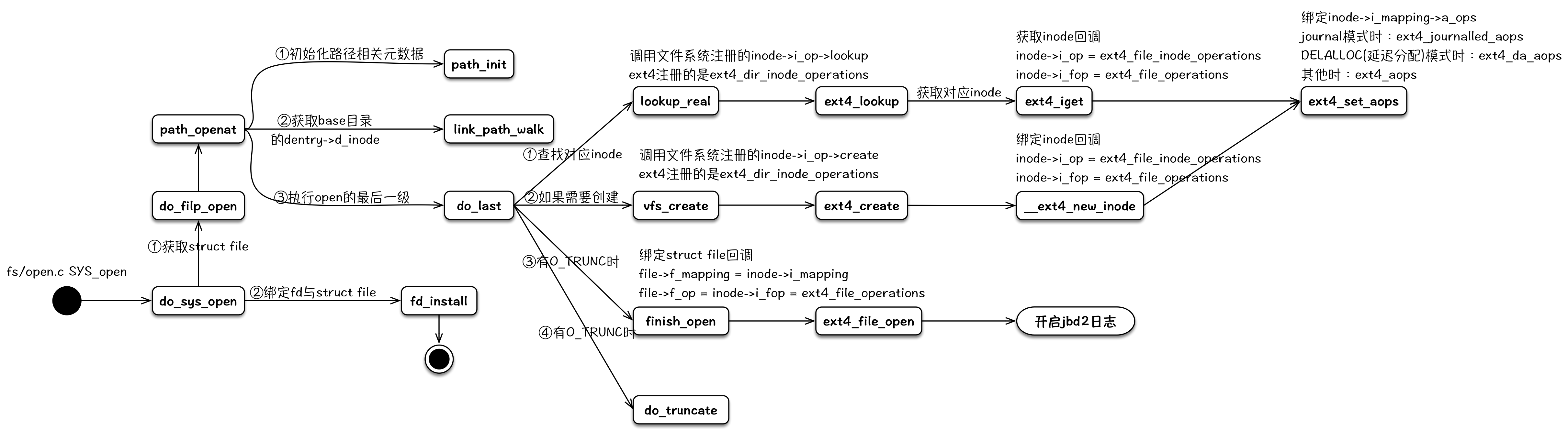
open
open负责在内核生成与文件相对应的struct file元数据结构,并且与文件系统中该文件的struct inode进行关联,装载对应文件系统的操作回调函数,然后返回一个int fd给用户进程。后续用户对该文件的相关操作,会涉及到其相关的struct file、struct inode、inode->i_op、inode->i_fop和inode->i_mapping->a_ops等。
注:文件操作对应的偏移存储于struct file中,每个open的文件单独维护一份,同一个文件的读写操作共享同一个偏移。
其整个内核逻辑流程可以用下图来表示:
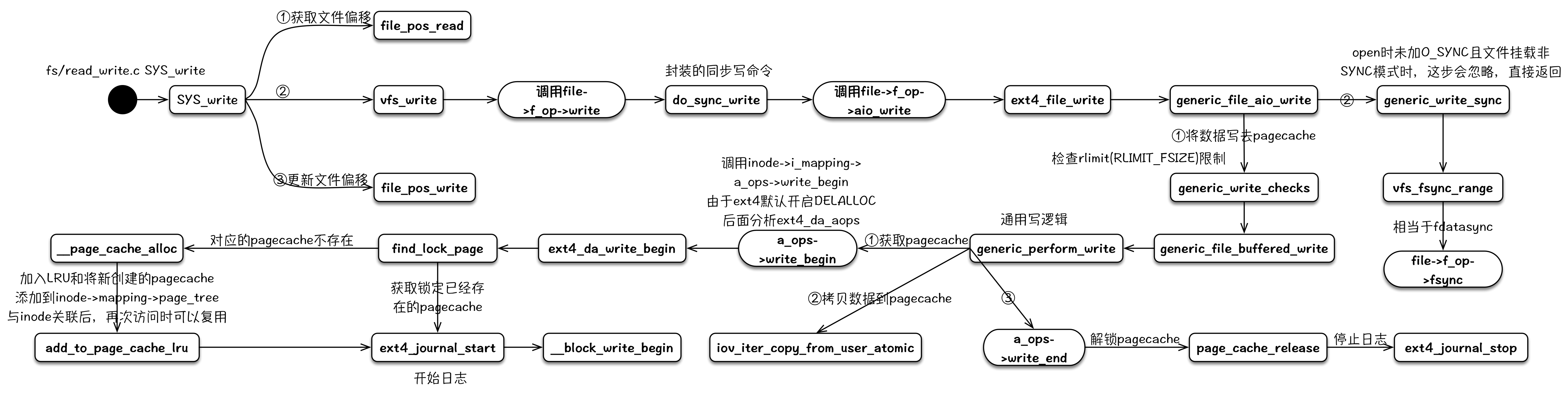
write
write的写逻辑路径有好几条,最常使用的就是利用pagecache延迟写的这条路径,所以主要分析这个。在write调用的调用、返回之间,其负责分配新的pagecache,将数据写入pagecache,同时根据系统参数,判断pagecache中的脏数据占比来确定是否要触发回写逻辑。其详细的代码分析可以参考:《Linux 内核写文件过程》和《Linux 内核延迟写机制》。
其整个内核逻辑流程可以用下图来表示:
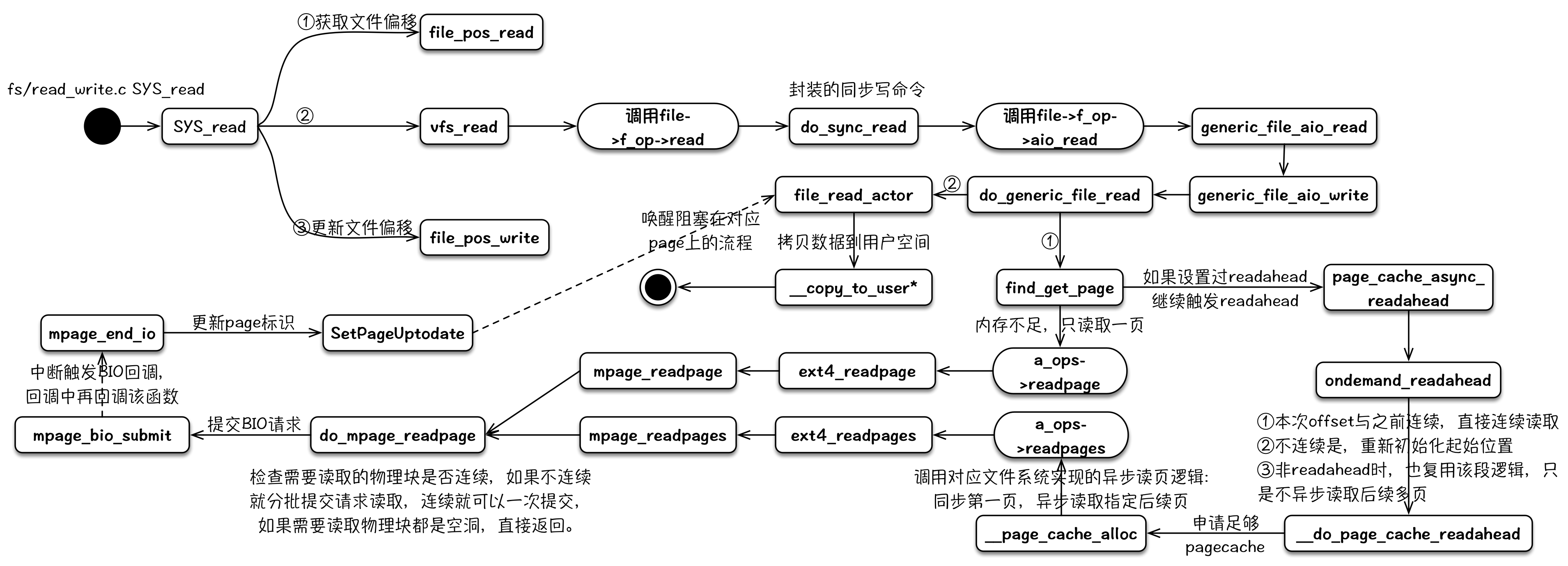
read
read的读逻辑中包含预期readahead的逻辑,其可以通过与fadvise的配合达到文件预取的效果。这部分的代码分析可以参考:《Linux 内核读文件过程》
其整个内核逻辑流程可以用下图来表示:
fsync/fdatasync
fsync和fdatasync主要逻辑流程基本相同。其通过触发对应文件的pagecache脏页回写,并且阻塞等待到回写逻辑完成,以达到同步数据的目的。
其整个内核逻辑流程可以用下图来表示: 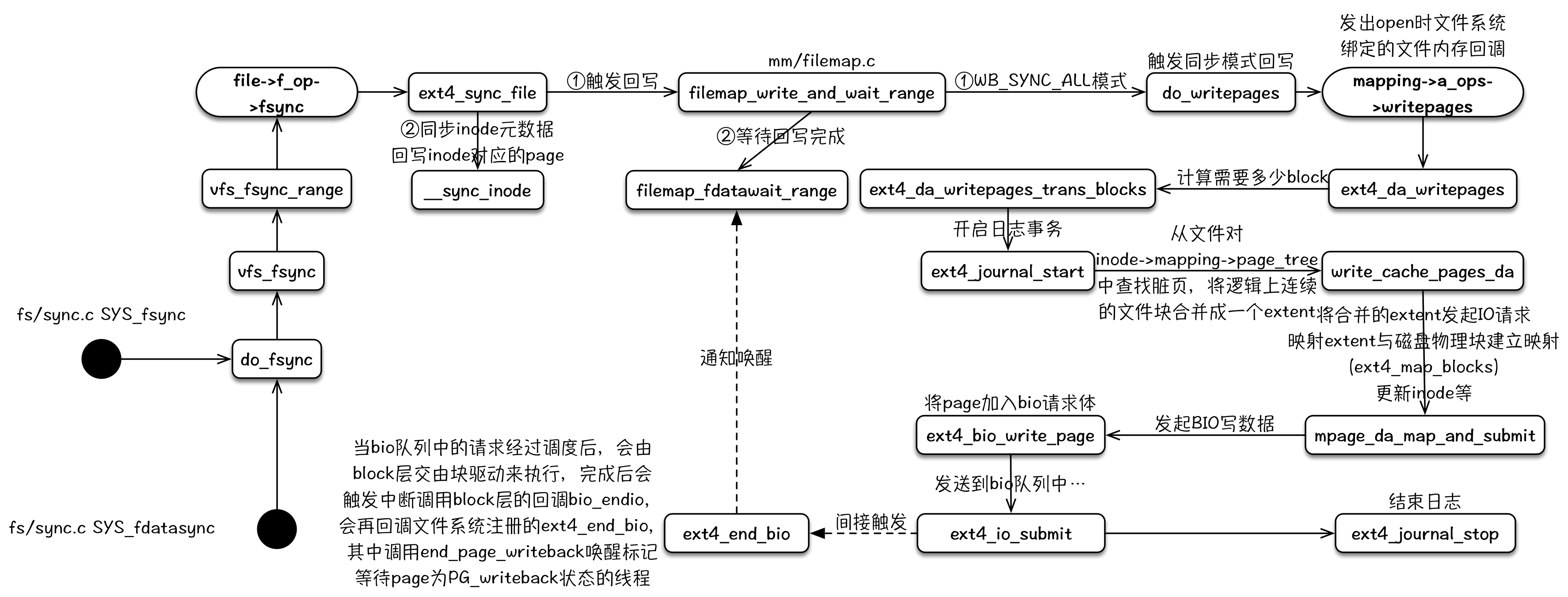
mmap
用户调用mmap将文件映射到内存时,内核进行一系列的参数检查,然后创建对应的vma,然后给该vma绑定vma_ops。当用户访问到mmap对应的内存时,CPU 会触发page fault,在page fault回调中,将申请pagecache中的匿名页,读取文件到其物理内存中,然后将pagecache中所属的物理页与用户进程的vma进行映射。
其整个内核逻辑流程可以用下图来表示,其中page fault部分比较简略,可以参考Linux Page Fault(缺页异常): 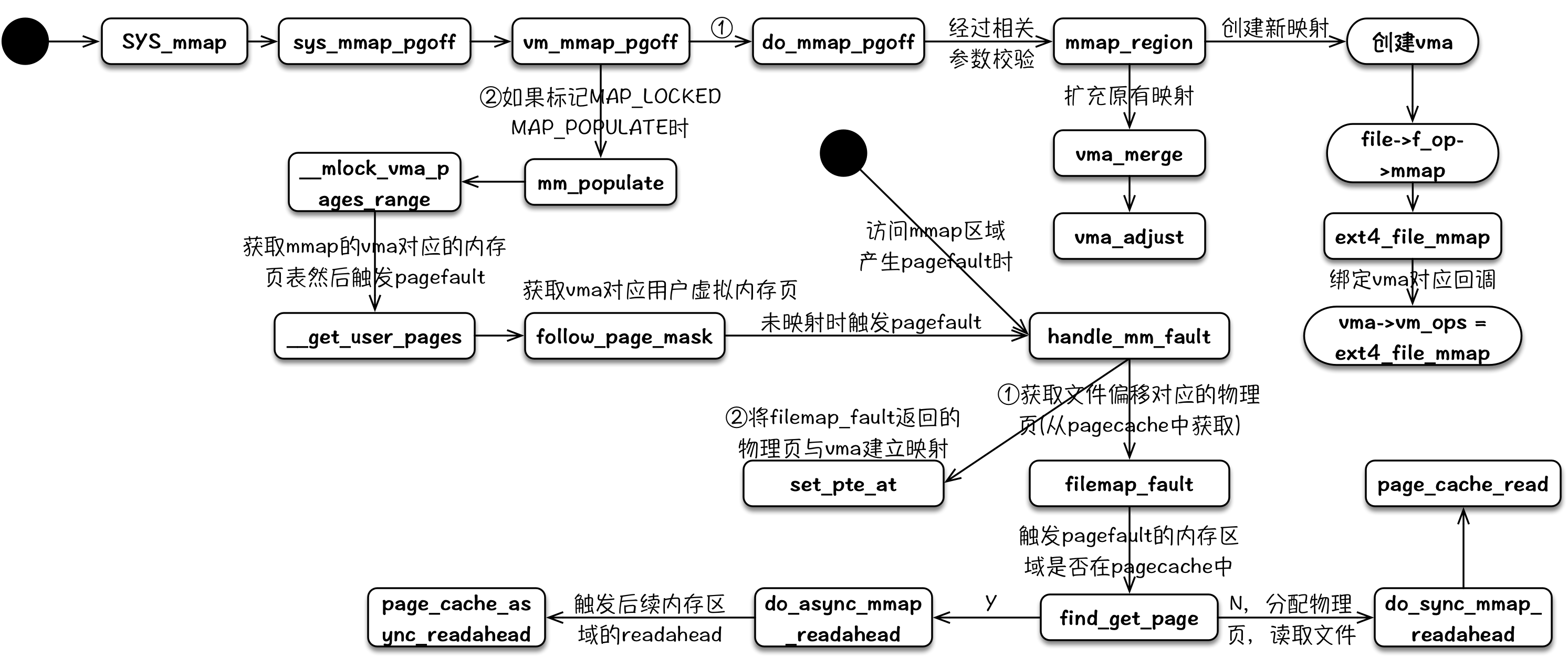
munmap

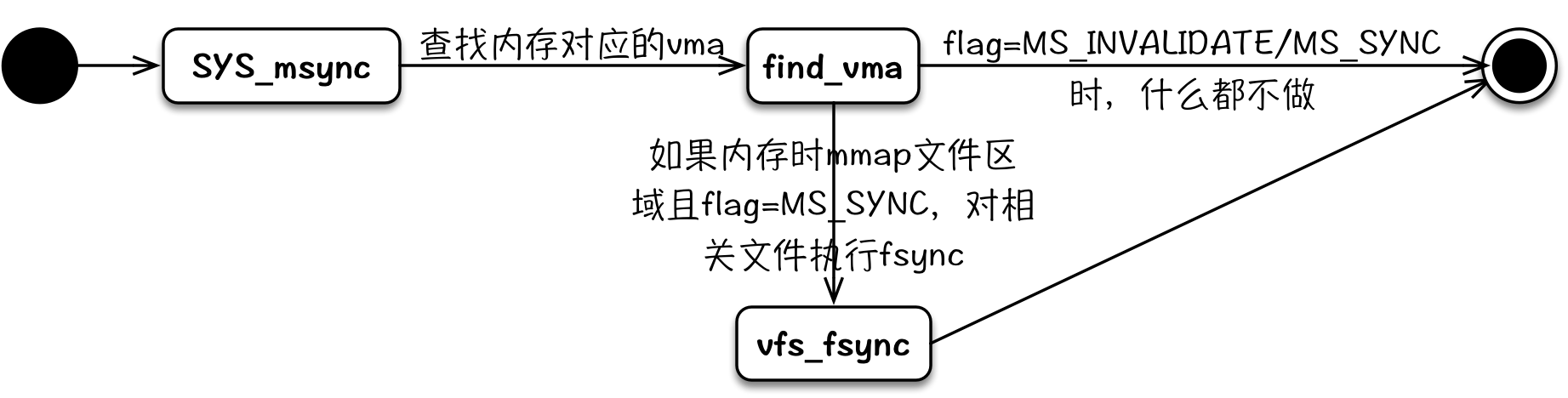
msync
msync的实际实现与其手册中的描述有很大不同,其调用时,flag=MS_SYNC等同于对mmap对应的文件调用fsync;flag=MS_ASYNC/MS_INVALIDATE其实什么都不执行。
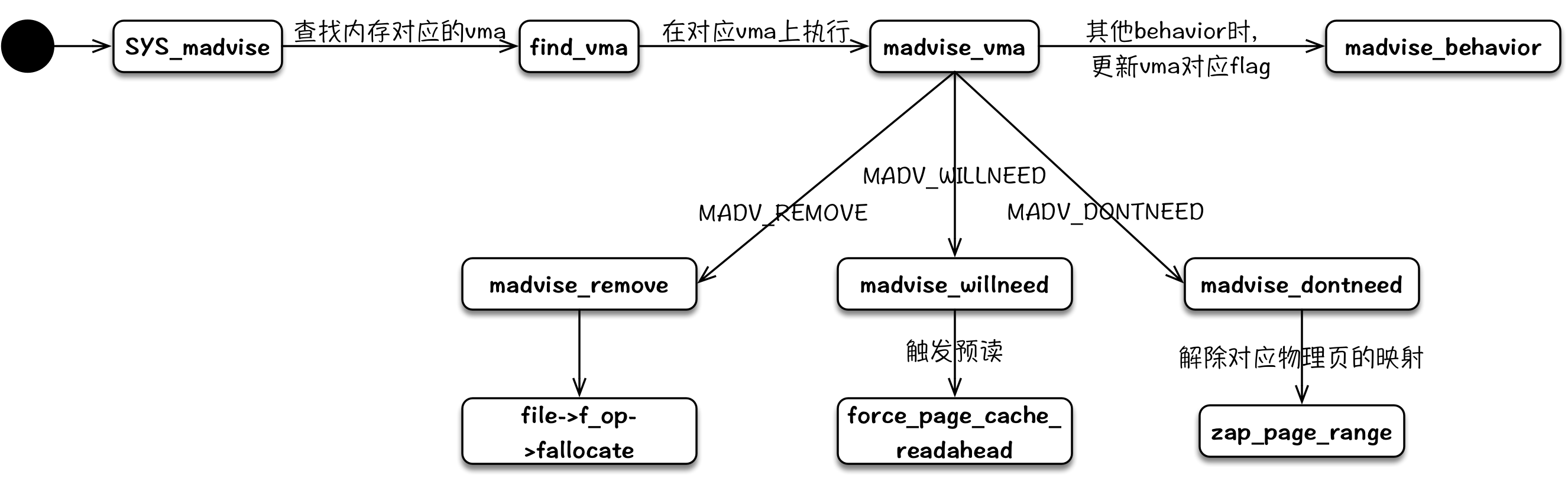
madvise
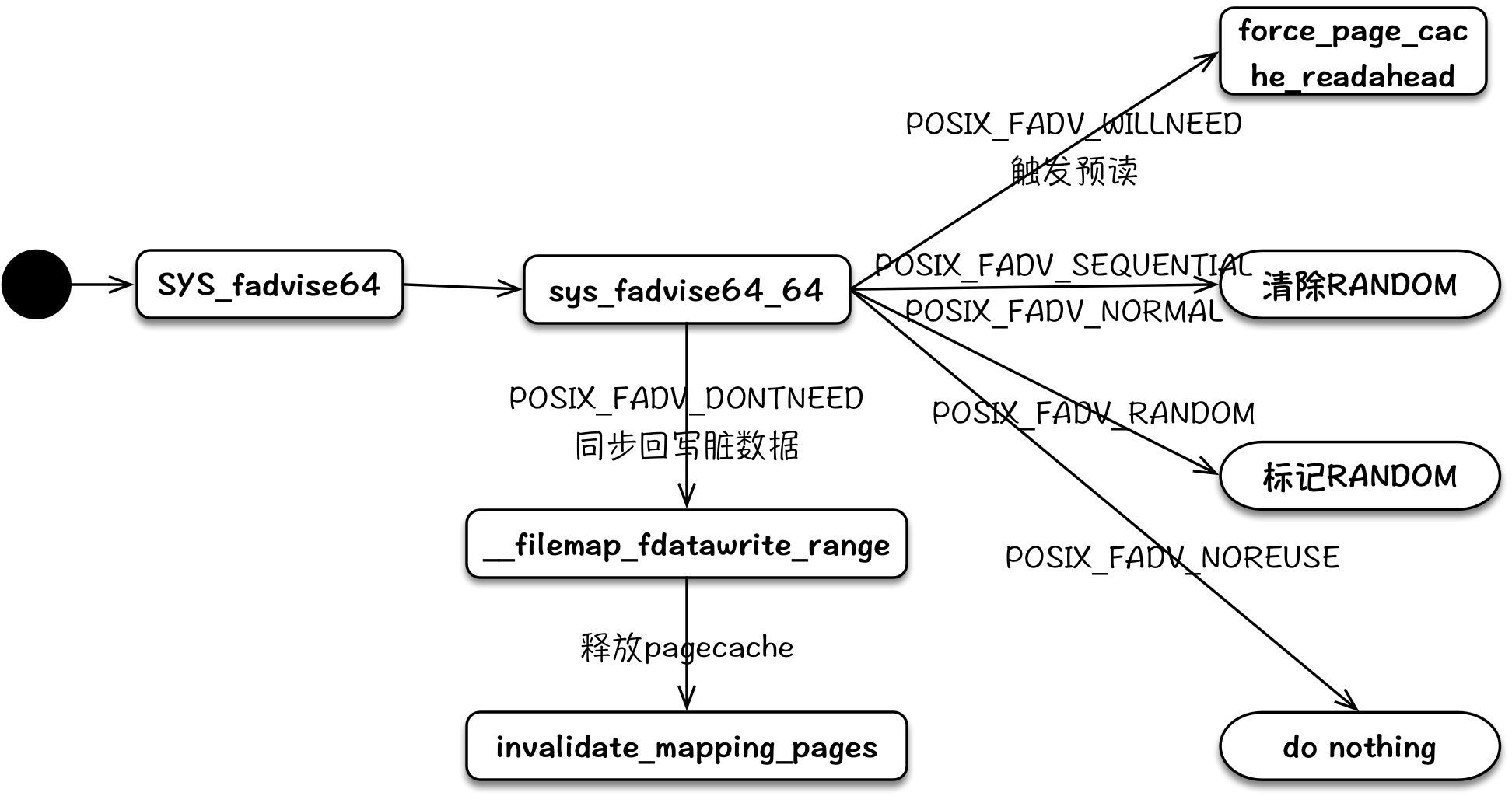
fadvise
io_sumbit
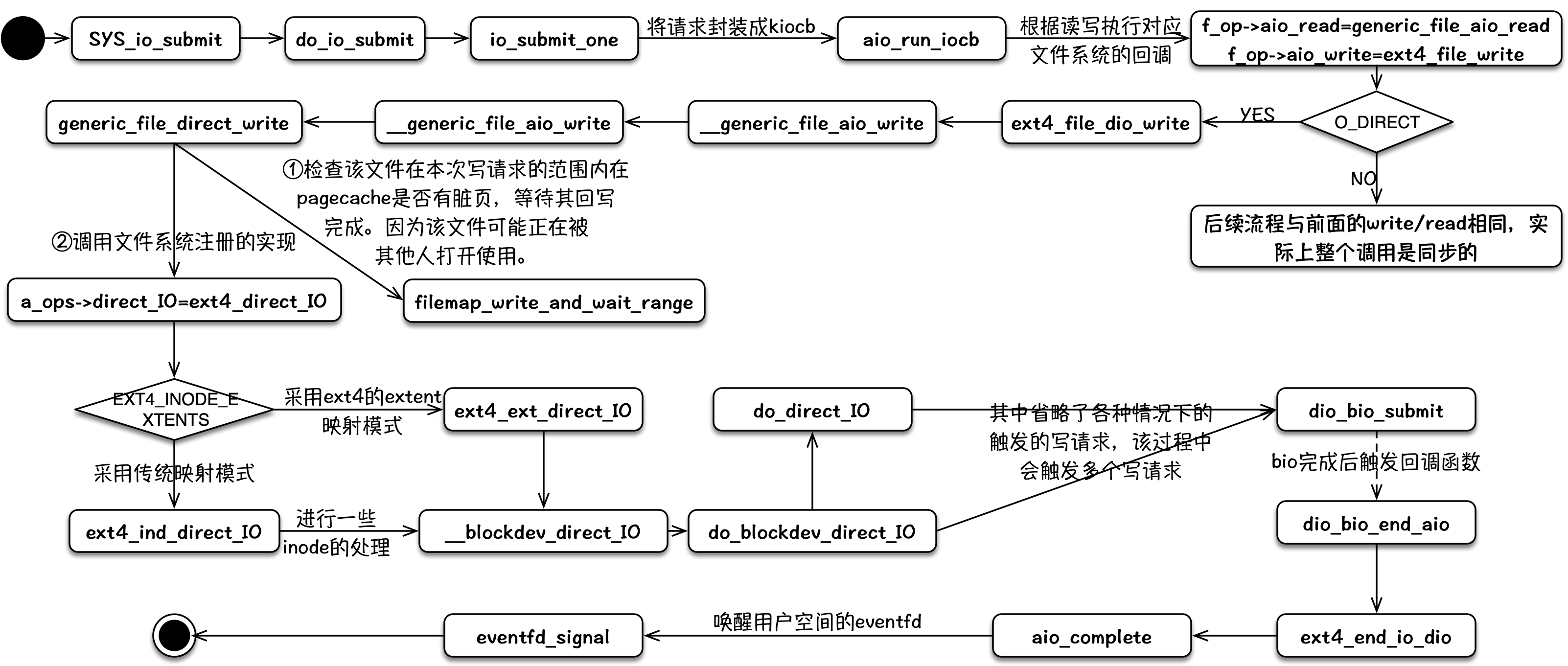
对于非O_DIRECT标记打开的文件,其内部逻辑与write流程基本一致,最终将数据拷贝到pagecache中,整个调用实际都是同步阻塞的。
对于O_DIRECT标记打开的文件,在文件系统层(vfs/ext4等)仍然是同步的,在一些文件系统日志、文件系统数据块与磁盘映射、bio 请求队列满等情况下,仍然会被同步阻塞。当经过文件系统层后,被封装成一个bio请求时,且 bio 请求队列未满时,该请求进入 bio 请求队列后即刻返回,从而形成一个异步写事件。
目前异步 IO 使用最多的是 linux native aio,不幸的是,其存在着诸多约束1:
- 最大的限制无疑是仅支持 direct io。而
O_DIRECT存在 bypass 缓存和 size 对齐等限制,直接影响了 aio 在很多场景的使用。而针对 buffered io,其表现为同步。 - 即使满足了所有异步 IO 的约束,有时候还是可能会被阻塞。例如,等待元数据 IO,或者等待 block 层 request 的分配等。
- 存在额外的拷贝开销,每个 IO 提交需要拷贝 64+8 字节(
iocb64 字节,iocbpp指针 8 字节),每个 IO 完成需要拷贝 32 字节,这 104 字节的拷贝在大量小 IO 的场景下影响很可观。同时,需要非常小心地使用完成事件以避免丢事件。 - IO 需要至少 2 个系统调用(submit + wait-for-completion),这在 spectre/meltdown 开启的前提下性能下降非常严重。
参考
文档信息
- 本文作者:Neal Hu
- 本文链接:https://lrita.github.io/2019/03/13/the-internal-of-file-syscall/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)