介绍
在lockfree编程中,很可能会出现ABA问题1。CAS22是很好、易用的一种避免该问题的并发原语。虽然 X86_64 提供了CMPXCHG16B3指令,可以帮助我们实现连续 128bit 的原子 CAS 操作,但是这对我们数据结构的布局(layout)又提出了苛刻的要求,并且平台相关性很强,因此适用场景有限。
在论文《A practical multi-word compare-and-swap operation》4中采用了二阶段 CAS 操作实现了CAS2语义,大多数平台都支持CAS语义,因此给我们带来了一种通用、易用的并发原语。同时,论文中还讲述了如何将其推广到CASN原语。
关于CASN的原语实现,已有一些方案,但是该方案与其他相比,有着易于实现、依赖要求低等优势:

double-compare single-swap (DCSS)
其提供语义的是:
// 当 *a1 == o1 且 *a2 == o2 时,将 *a2 改为 n2
word_t RDCSS(word_t *a1, word_t o1, word_t *a2, word_t o2, word_t n2) {
word_t r = *a2;
if ((r == o2) && (*a1 == o1))
{
*a2 = n2;
}
return r;
}
其中a1为控制区,a2为数据区,在RDCSS原语中,只修改数据区的内容,如果需要读取数据区的内容,需要使用RDCSSRead原语。
实现
该实现对运行环境有几点要求,这两项要求是非常容易被满足的,多数平台都已支持:
- 新分配对象的内存会出现在新的内存区域(简单来说就是,新分配对象的内存地址不会与已存在对象的地址重复。例如共享栈、拷贝栈等栈上的内存可能在生命周期被复用,不利于
CAS操作,发生 ABA 问题。) - 内存地址达到
字长度,并且内存对其(访问时可以原子操作,内存对其时地址低位可以存储私有数据)。
关于RDCSS的实现,其一共需要两个方法,读(RDCSSRead)和写(RDCSS)方法,还需要一个辅助类(RDCSSDescriptor_t),用来存储CAS2过程中的上线文:
struct RDCSSDescriptor_t {
word_t *a1; // control address
word_t o1; // expected value
word_t *a2; // data address
word_t o2; // old value
word_t n2; // new value
}
写方法的调用者,需要创建一个新的RDCSSDescriptor_t,将控制字段与值字段等存储在该上下文中,然后调用写方法(RDCSS):
// 为了讲解方便,将相关逻辑写在一行内。
word_t RDCSS(RDCSSDescriptor_t *d) {
do {
r = CAS1(d->a2, d->o2, d) // C1-先LOCK数据区,锁定第一个相等的条件:a2==o2,此后数据
// 区a2的位置将不能再被其他线程修改
if (IsDescriptor(r)) Complete(r); // H1-此处保证lockfree的progress,及时之前一个对数据区a2
// 调用RDCSS的线程在CAS1之后被阻塞或者崩溃了,其CAS1之后的
// 后续工作仍然会被下一个调用RDCSS的线程发现并且继续完成
} while (IsDescriptor(r)); // B1-完成所有未决的RDCSS操作
if (r == d->o2) Complete(r); // X1-此处 r == d->o2 是一种缓存优化,因为读的效率远比CAS的
// 高,如果此处不预先判断,Complete中的CAS导致的性能损失更高。
return r;
}
word_t RDCSSRead(word_t *addr) {
do {
r = *addr; // R1-读取数据区的VALUE,帮助完成全部未决的RDCSS操作。
if (IsDescriptor(r)) Complete(r); // H2-作用同H1
} while (IsDescriptor(r)); // B2-作用同B1
return r;
}
void Complete(RDCSSDescriptor_t *d) {
v = *(d->a1); // R2-读取a1原值
if (v == d->o1) CAS1(d->a2, d, d->n2); // C2-如果a1==o1,则完成a2赋值
else CAS1(d->a2, d, d->o2); // C3-如果a1!=o1,则回滚
}
关于IsDescriptor的实现,需要明确的是:如果变成语言层面没有提供从指针来识别类型的方法时,我们可以利用内存分配对其时低 n 位永远为 0 的特性,将标识符存储于RDCSSDescriptor_t的低 n 位中。
正确性
该实现为一个非阻塞线性算法。在C1处使得仅有一个线程可以强占数据区,并使用自己的描述符进行标志,其他线程只能不断尝试,直到循环B1/B2终结。C2/C3会释放数据区,并移除描述符标识。因此并发访问的不同线程,各自有一次机会使得自己的描述符强占数据区。首先RDCSSRead相对于RDCSS一定是线性的,因为RDCSSRead一定会在数据区不被强占的时刻才能终结B2,因此RDCSSRead一定完成在RDCSS开始之前或RDCSS结束之后。即,下图中两种情形,都满足线性要求。

不同线程也可以并发调用RDCSS:
- 当多个线程并发修改同一个数据区时,只有一个线程可以抢占该数据区,其他的线程在被抢占期间只能失败,在
X1处放弃RDCSS更新。显而易见,同时满足线性要求。 - 两个线程并发调用
RDCSS,各自的数据区与控制区调换时,比如有两块内存区域m1和m2,线程一的RDCSS调用中,控制区为m1,数据区为m2,线程二的RDCSS调用中,控制区为m2,数据区为m1。这里没有想到太好的证明方法,原论文中也写的比较简单,没有充分理解。所以这里采用归纳法才进行解释。一个完整的
RDCSS需要经过C1、R1和C2/C3三个步骤,下面按照两个线程并发调用RDCSS时,各自步骤之间组合关系来归纳。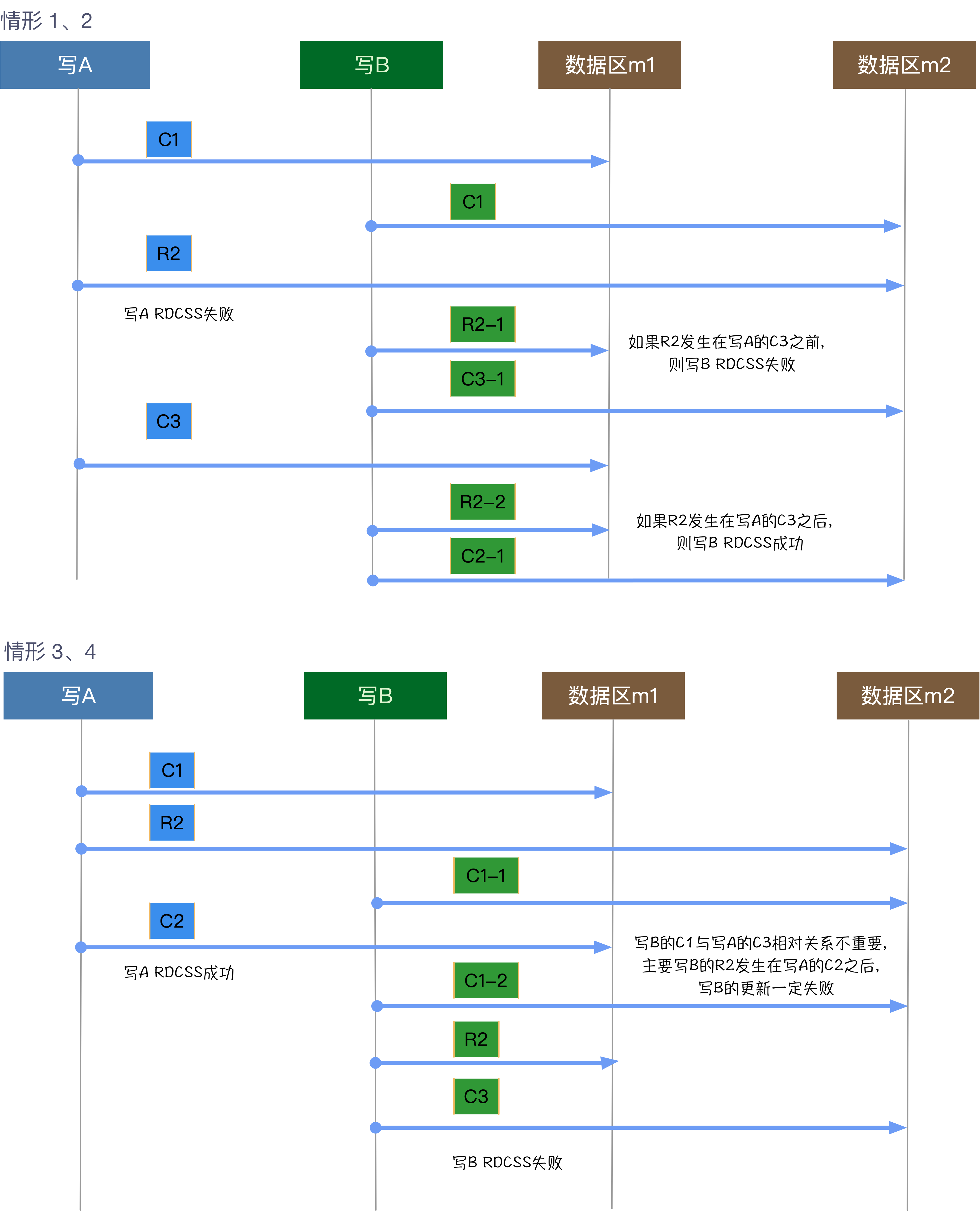
- 当两个线程并发调用
RDCSS,且各自只有一个数据区或控制区重合时,与前者类似。
注意:在R2处使用一般的AtomicRead即可,不要使用RDCSSRead,否则在多个线程并发修改两个关联的值时,可能造成相互依赖,从而死锁。在下面举例的ctrie中,使用了一种可以中断取消的RDCSSRead来避免死锁问题。我在阅读的相关内容后,任务其完全可以使用AtomicRead,并不影响相关逻辑的正确性,也避免了在Complete中调用RDCSSRead死锁的风险。
应用
参考Concurrent Tries with Efficient Non-Blocking Snapshots实现的ctrie中使用了该技术。ctrie是一个支持并发、lock-free的HAMT5。其依赖在每层分支节点间增加一个INode来间接引用解决了多个并发修改之间COW可能引起的丢失数据问题:
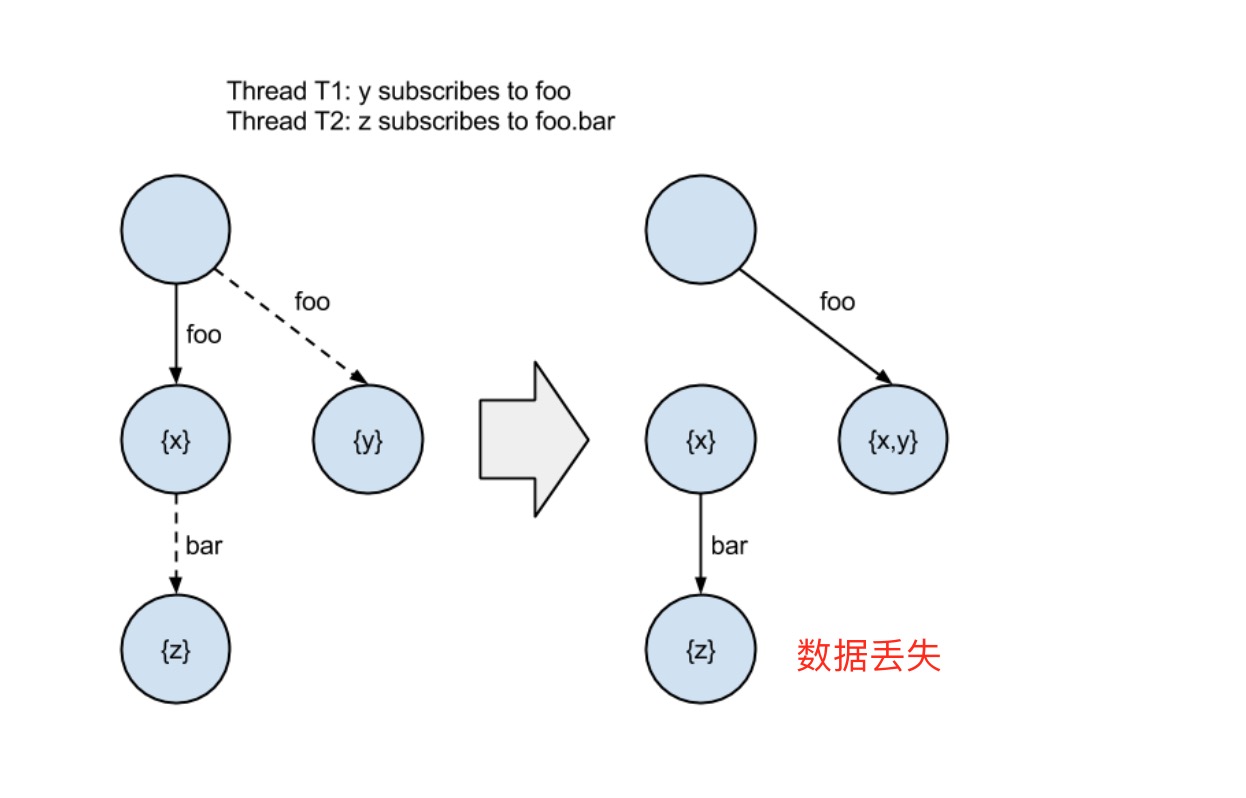
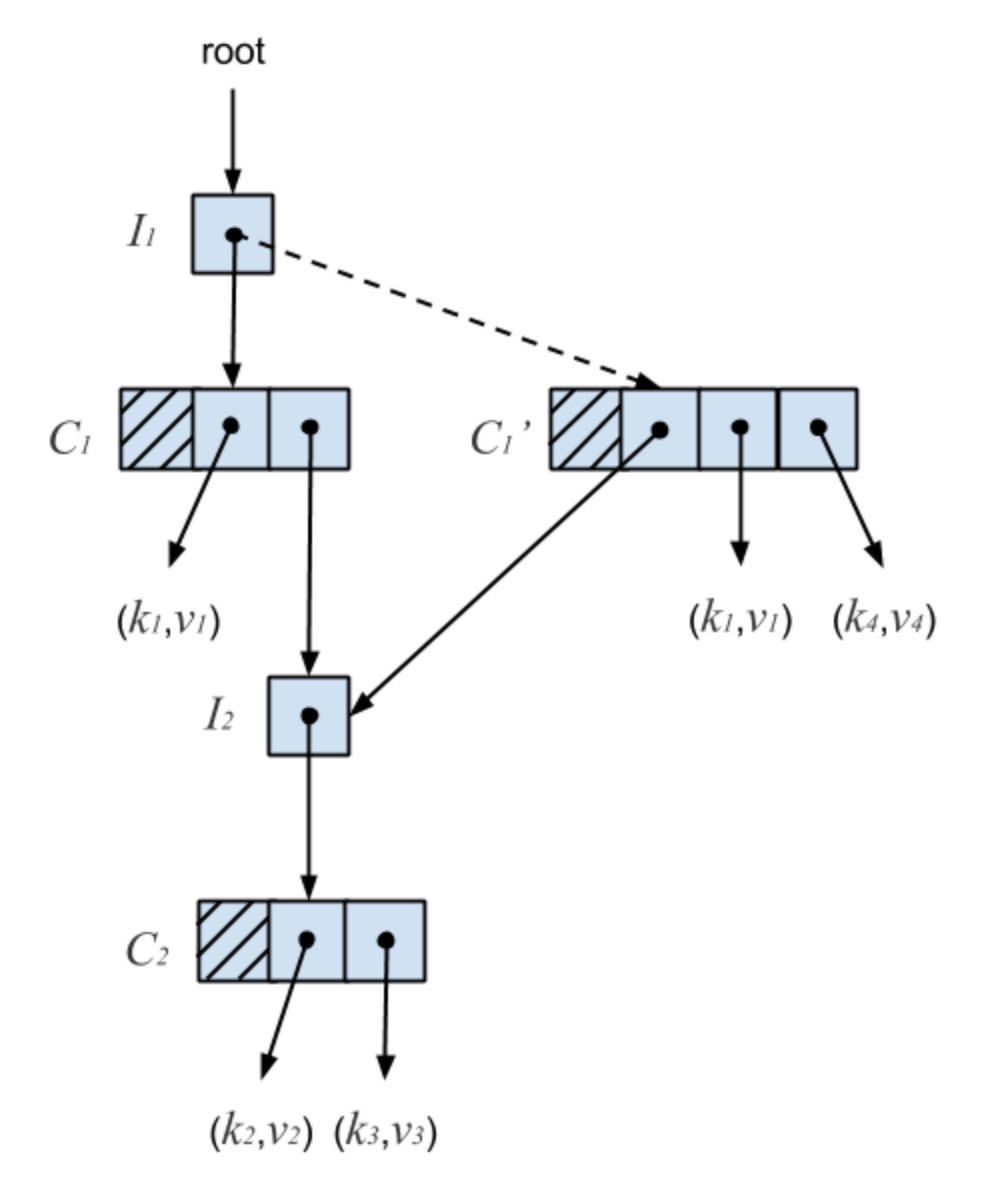
其实在ctrie的增删改查时,都不需要CAS2指令。但是其为了保证snapshot方法的线性性,则需要使用CAS2指令,在这个数据结构中,其该改造成GCAS(generation-compare-and-swap)。从之前讲到的HAMT结构,其增改方法是一个很长的并发过程,而为了保证在snapshot方法的线性性,则需要在snapshot和增改方法之间做一个同步或者barrier,使得所有的正在并发的增改方法完成与snapshot之前,或者snapshot之后所有正在并发执行的增改方法都失败。为了不引入锁等排他原语,ctrie使用的generation的实现,每生成一个snapshot,只需要将当前ctrie的generation增加,其他操作在判断到generation变更时,自动失败,这样既保证了snapshot的线性性,又通过COW使得snapshot成为一个O(1)的操作。
扩展到 CASN
我们完全可以将RDCSS推广到修改 N 个值的一般情况。当我们需要修改 N 个值时,则我们需要在C1抢占 N 个值,则该过程不可能是一个原子操作,则需要使用三个状态来表示抢占过程:UNDECIDED、FAILED和SUCCEEDED。其他步骤与上面类似。关于具体的实现,可以参考verifast-mcas
参考
文档信息
- 本文作者:Neal Hu
- 本文链接:https://lrita.github.io/2019/09/04/lockfree-RDCSS/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)