注:关于
一致性模型这个话题,之前存档了很多笔记,最终还是需要再整理一遍,整合一篇自己的理解。相关自己的独家认识并不多,因此多是一些摘抄的整合。
一致性概念
一致性会在不同场景下被提及,其代表的含义也经常不同,对应的英文术语也是不一样的:Consistency,Consensus,Coherence等等。因此一致性是一个跨领域综合学科的名词,大概是最容易造成困惑的概念之一,因为它已经被用烂了。
首先,结合下图阐述一下自己对一致性概念在不同场景下的理解:
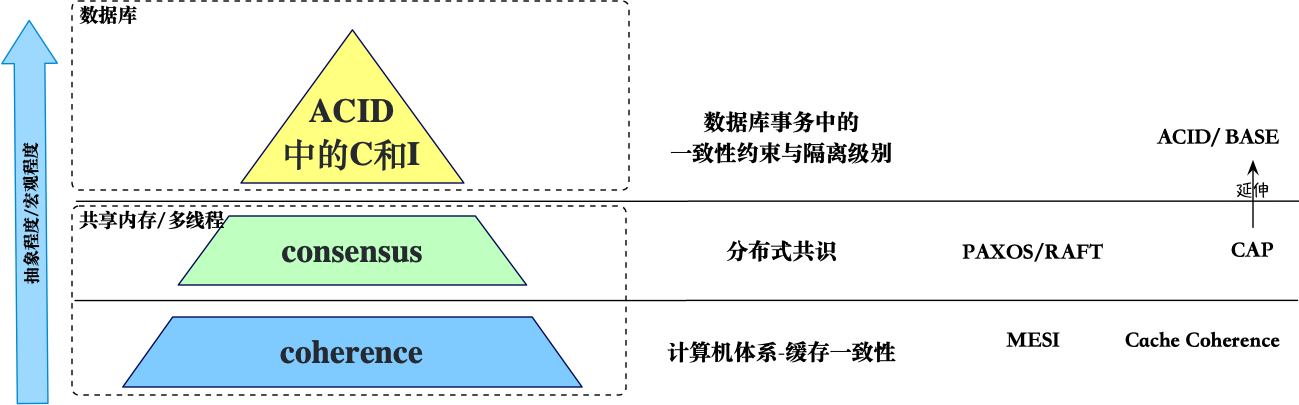
一致性概念主要出现在数据库与(分布式)共享内存/多线程两个主要领域。
- 在
(分布式)共享内存/多线程领域,一致性通常指在并发 (Concurrency) 编程中,进程与数据存储(寄存器、内存、K-V 存储等)之间的一种契约,如果进程遵循某些规则,那么进程对数据的读写操作都是可预测的1。这里可预测是非常重要的,它保证程序逻辑的正确性。例如,操作x=1;x=2后,契约保证存储器x的结果一定是2,或者可能是1或者2,这都提供了一种可预测保障,我们可以根据这种契约执行后续的逻辑。如果进程与数据存储之间的没有一种契约,那我们将无法进行编程。现实中,在该领域,存在多种一致性模型(Consistency Model),即不同的类型的契约,后面会分别进行分析。在共享内存/多线程这个模型下,我们又可以分为单进程多线程和多进程(分布式)两种场景:- 缓存一致性,
Coherence这个单词只在Cache Coherence场景下出现过,它关心的是多核共享内存的 CPU 架构下,各个核的 Cache 上数据如何保持一致。在现代的 CPU(大多数)上,所有的内存访问都需要通过多级缓存来进行,每个 CPU 核心分别独享、共享不同层级的缓存,CPU 内部需要保证不同 CPU 核心的缓存之间的数据一致性,其就像微观层面的分布式系统一样。其常用的缓存一致性协议有 MESI 等。可以参考《缓存一致性入门》。 - 分布式场景下,
一致性可以理解为Consensus。在多进程分布式场景中,我们也需要一套协议来保证进程与数据存储之间的契约。比如 Paxos、Raft 等共识算法本质上解决的是如何在分布式系统下保证所有节点对某个结果达成共识,其中需要考虑节点宕机,网络时延,网络分区等分布式中各种问题。类似的,区块链中非常重要的一部分也是共识算法,但通常使用是 POW(Proof of Work) 或 POS(Proof of Stake),这类共识算法通常适合用在公网,去中心化的情形下。
- 缓存一致性,
- 在
数据库领域,一致性通常指在数据库系统中并发执行多个事务时的一致性,包括外键约束,级联,触发器等,即ACID中的C。在事务开始之前和事务结束以后,都必须遵守这些不变量,保证数据库的完整性不被破坏。更让人崩溃的是,在日常谈论中,经常会将事务的隔离性(I)也混淆在一致性里面。因此后面也会谈论到他们。
一致性模型
不确定性(并发关系)
多数编程语言都是面向过程或者面向对象的,其描述的是系统状态的转移关系,当系统运行时,总是随着操作从一个状态转移到另一个状态。在描述程序状态转移时,我们需要考量三个因子:时间,事件,和顺序。时间、事件我们是很容易理解的,而顺序是我们不容易深入理解的,而且过分明确事件发生的实际顺序往往是没有意义的。
例如,我们的状态可以是一个变量x,操作状态的可能是读写命令,我们可以用下面这段代码演示一下状态的转移2:
x = "a"; puts x; puts x
x = "b"; puts x
x = "c"
x = "d"; puts x
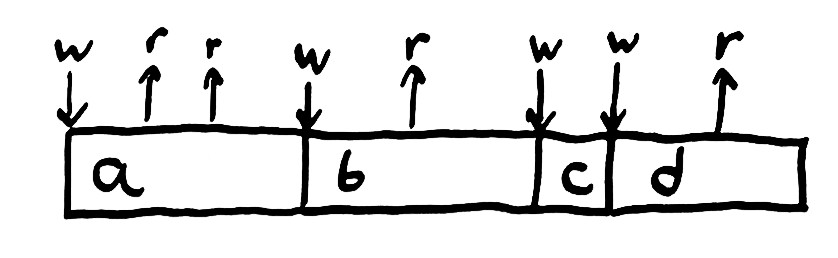
我们可以根据这段代码准确的预测系统在任一时刻的状态,因为使系统状态转移的操作都是顺序的、串行的,而且系统状态是单一的,无副本的。然而在并发(Concurrency) 编程中,我们却不能这样简单设想,任何操作都不能原子的。
多个进程或线程对同一个全局资源进行操作,操作过程中会消耗时间,最快的可能一个时钟周期完成,慢的可能需要几百个时钟周期,也就意味着,每个操作可能在发送请求到接收到响应之间的任意时间点发生。例如对于写入操作,在实际开始写入,到写入完成,再到其它线程读取到,都需要经历一个过程。
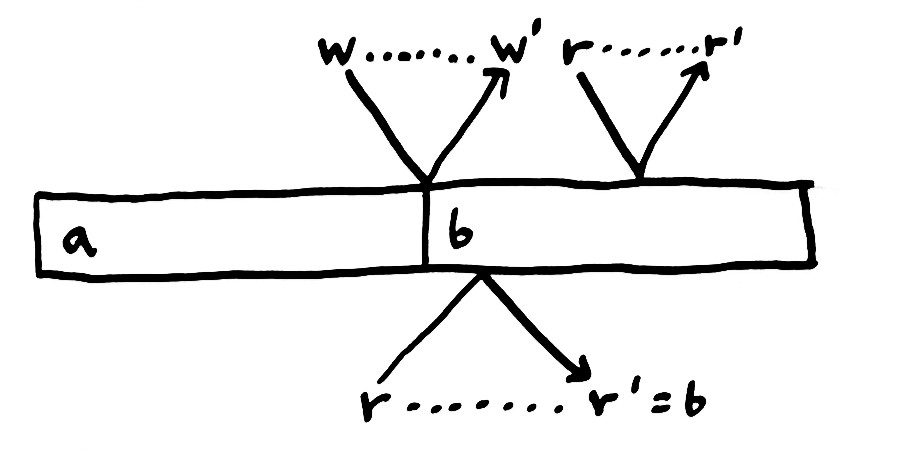
在现实中,CPU 距离物理内存有几十厘米远,电信号传播也得数纳秒时间。不同服务之间的信号传播至少得几百微秒以上。跨地域的数据中心之间,信号传播得十几毫秒以上。每个操作需要信号一来一回,我们才能知道操作是否真实发生,是否成功。这意味着每个操作都有一个物理上的延时,在这个延时区间内,系统的状态,不再是可预测。当多个操作同时发生时,它们的操作的延时有重叠时,我们将无法预测他们真实发生时的顺序,在这种情形下追求明确他们的顺序是没有意义的,我们称这些操作之间是并发关系。虽然,并发操作之间有着某种物理时钟上的先后顺序,但是在逻辑顺序我们认为他们同时发生(如果在分布式场景中,我们认为他们在逻辑时钟上同时发生)。如上图,上半部的写操作和读操作不存在并发关系,则读操作的结果可以被预测,不受操作延时变化的影响;而下半部的读操作与上半部的写操作并发,如果读操作的延时更小,则可能读到写操作实际发送之前的值,如果读操作的延时大,则可能读到写操作实际发生后的值。
确定性
前面讲到了,一致性通常指在并发 (Concurrency) 编程中,进程与数据存储(寄存器、内存、K-V 存储等)之间的一种契约,如果进程遵循某些规则,那么进程对数据的读写操作都是可预测的。这种契约通常通过描述在非物理时间的并发操作下,状态变化可见性的时效性来表述。如果一个说某种一致性A强于另一种一致性B,则在一致性模型A的场景中,一个线程修改状态后,这种状态能被其他其他线程可见的时效性强于一致性模型B。
一致性模型分类
目前,基本都是从两个角度看一致性模型:data-centric consistency model和client-centric(user-centric) models。前者是从系统中数据的状态角度出发探讨一致性模型,后者是从客户端的角度出发探讨的3。
Data-Centric Consistency Models
Linearizable Consistency(线性一致性)
线性一致性是程序可以实现的最强的一致性模型,其形式化定义可以参考《Linearizability: A Correctness Condition for Concurrent Objects》,原始论文中线性一致性是基于 single-object (e.g. queue, register) 以及 single-operation (e.g. read, write, enqueue, dequeue) 的模型来定义的。通常 CAP4 中所说的一致性就是指线性一致性。
根据前面描述的系统状态转换的过程:
- 每个操作包括了请求 (Invocation) 和响应 (Response) 两个事件,而且请求一定早于响应。
- 每个操作的实际生效时间在请求和响应之间的任意时间。
则,线性一致性模型要求:
- 从(分布式)系统外部(客户端/调用者)看,每个操作(读/写)都是原子的,对于这些原子操作,有一个严格执行(基于物理时间)的顺序;这里的顺序可以理解为,如果事件 A 请求时间晚于事件 B 响应时间,则能够保证 B 发送在 A 前,另一层意思就是 A 如果是读请求,则必须能获得写请求 B 的修改结果,因此线性一致性禁止了非单调的读。
- 且每个系统外部观察者,观察到的系统状态变化都是相同顺序的。可以理解为如果操作 A 生效了,则即刻对全部客户端可见。
- 当读写操作并发时,或者多个读写操作并发时,则他们的操作顺序可能为其各种排列组合中的一种,即读到的数据可能是其中一种结果。
我们可以举例来说明5:
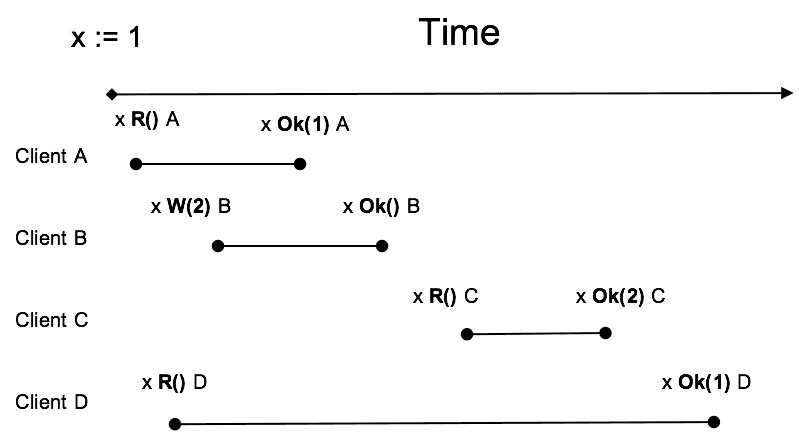
先下结论,上图表示的行为满足线性一致。
对于同一个对象 x,其初始值为 1,客户端 ABCD 并发地进行了请求,按照真实时间(real-time)顺序,各个事件的发生顺序如上图所示。对于任意一次请求都需要一段时间才能完成,例如 A,“x R() A” 到 “x Ok(1) A” 之间的那条线段就代表那次请求花费的时间,而请求中的读操作在 Server 上的执行时间是很短的,相对于整个请求可以认为瞬间,读操作表示为点,并且在该线段上。线性一致性中没有规定读操作发生的时刻,也就说该点可以在线段上的任意位置,可以在中点,也可以在最后,当然在最开始也无妨。来看看上图中 x 所有可能的值,显然只有 1 和 2。四个次请求中只有 B 进行了写请求,改变了 x 的值,我们从 B 着手分析,明确 x 在各个时刻的值。由于不能确定 B 的 W(写操作)在哪个时刻发生,能确定的只有一个区间,因此可以引入上下限的概念。对于 x=1,它的上下限为开始到事件“x W(2) B”,在这个范围内所有的读操作必定读到 1。对于 x=2,它的上下限为 事件“x Ok() B” 到结束,在这个范围内所有的读操作必定读到 2。那么“x W(2) B”到“x Ok() B”这段范围,x 的值是什么?1 或者 2。由此可以将 x 分为三个阶段,各阶段”最新”的值如下图所示:
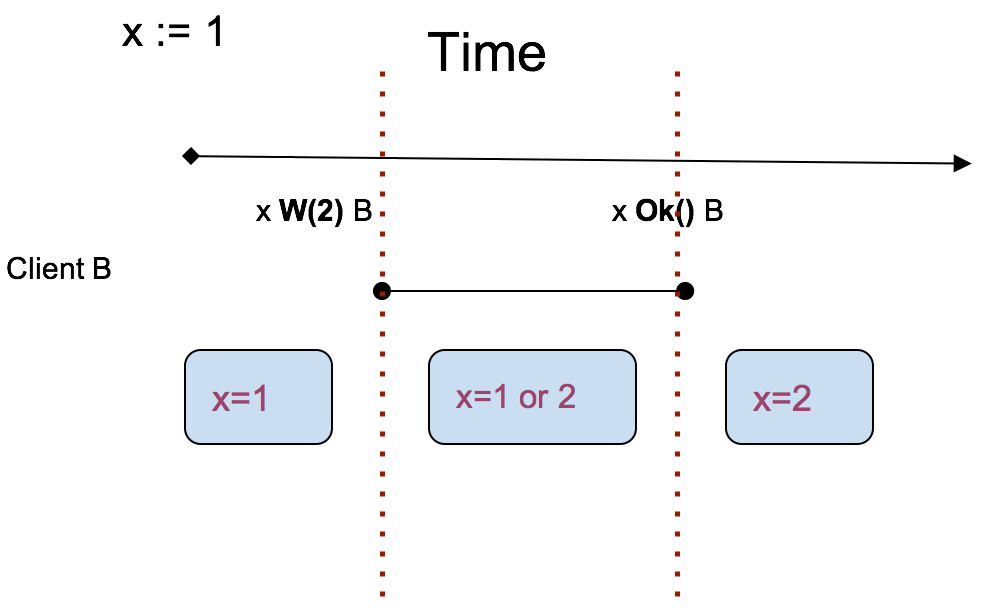
清楚了 x 的变化后理解例子中 A C D 的读到结果就很容易了。最后返回的 D 读到了 1,看起来是 “stale read”,其实并不是,它仍满足线性一致性。D 请求横跨了三个阶段,而读可能发生在任意时刻,所以 1 或 2 都行。同理,A 读到的值也可以是 2。C 就不太一样了,C 只有读到了 2 才能满足线性一致。因为 “x R() C” 发生在 “x Ok() B” 之后,可以推出 R 发生在 W 之后,那么 R 一定得读到 W 完成之后的结果:2。
Sequential Consistency(顺序一致性)
在 Herlihy & Wing 提出线性一致性之前,Lamport 早在 1979 年就提出了顺序一致性(Sequential consistency)的概念:
A multiprocessor system is sequentially consistent if the result of any execution is the same as if the operations of all the processors were executed in some sequential order, and the operations of each individual processor appear in this sequence in the order specified by its program.
值得注意的是,Lamport 上述的定义是基于shared-memory multi-processor system的。我们可以将这种系统理解成一个同步分布式模型,从而扩展该定义到分布式系统领域。这个定义实际上对系统提出了两条访问共享对象时的约束:
- 从单个处理器(线程或者进程)的角度上看,其(自己的)指令的执行顺序以编程中的顺序为准;
- 从所有处理器(线程或者进程)的角度上看,全部指令的执行保持一个单一(某种不确定的,依赖实际情况生成的特定)的顺序,且所有处理器观察到的顺序相同;
更通俗的理解是,将整个(分布式)系统想象成一个调度器,将多个进程的请求看做是多个 FIFO 请求队列,调度器依次处理队列中的请求,并在多个队列中不断切换。每个 FIFO 请求队列中的请求执行是按变成顺序的,但是全部 FIFO 请求队列中的请求执行是按照某种(确定的)顺序执行的,每个外部程序观察到的顺序也是相同的。由于其不要求全部请求按照实际发生(物理时间)顺序,因此其弱于线性一致性,但操作必须是原子的。
例如6:
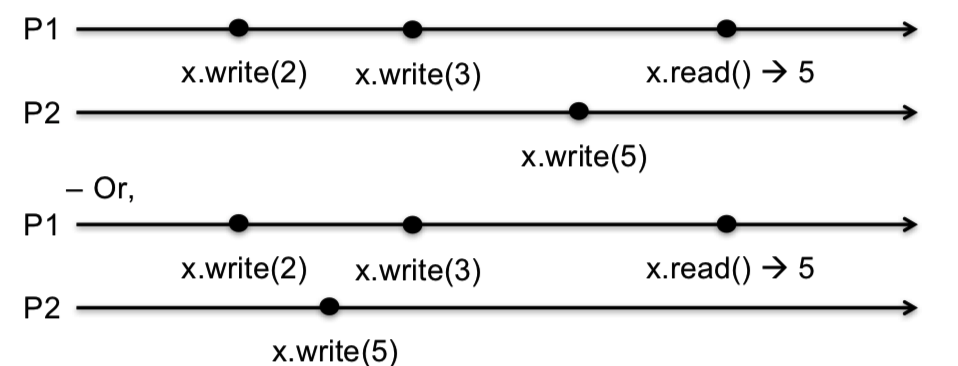
这两种情况我们都可以找到一个满足上述两个约束的执行顺序,即:P1 x.write(2) -> P1 x.write(3) -> P2 x.write(5) -> P1 x.read(5),这表明其执行结果满足顺序一致性。而下图这部满足顺序一致性的定义,因为没有保证 P3、P4 相同的观察顺序。
关于线性一致性与顺序一致性在性能上的区别,色列科学家 Hagit Attiya 和 Jennifer Welch 在 1994 年发表的论文(Sequential Consistency versus Linearizabiltiy, ACM Transactions on Computer Systems, Vol 12, No 2, May 1994, Pages 91-122)给了大家一个定性的分析7:
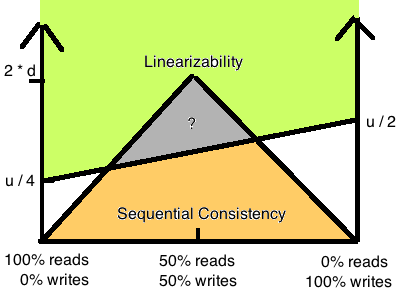
假设我们的网络延迟有一个上限 d (尽管现实中不可能,这里纯粹做理论分析用),那么最慢和最快的请求波动在 u 以内。论文证明了下图中上半部分绿色四边形是 Linearizability 的性能根据读写比例从 u/4 到 u/2,下面黄色三角形是 Sequential Consistency 的性能,最糟糕不会超过 d * 2。从性能角度来看,二者的差别还是巨大的。
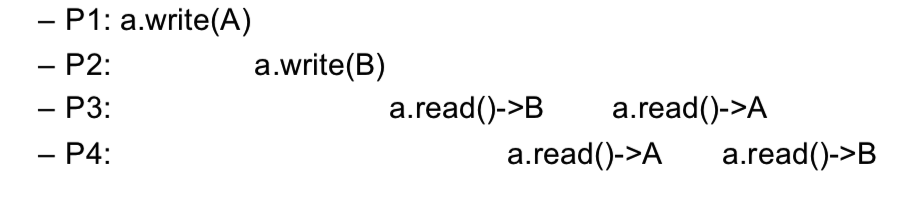
Causality Consistency(因果一致性)
因果一致性只要求有因果关系的操作保证其顺序性,无序保证所有操作的顺序性,其因果关系体现在happen-before关系及其传递闭包,即因果关系的偏序传递:
- 同一个进程内的事件 A 早于 B (program order)
- A 完成后发消息通知触发 B
- 已知 A<B,B<C,根据传递性质推到出来的 A<C
Causal Consistency 要求,如果两个事件有因果关系,则要求这两个事件的先后顺序满足因果序,并且所有进程看到的这两个事件的顺序都是满足这个因果序的。
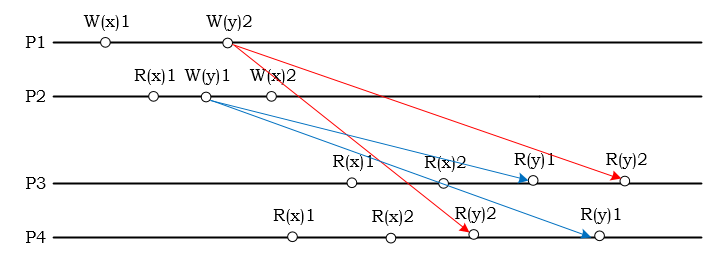
如图示,P2 把 x 从 1 改成 2,因此读取操作不允许出现 R(x)2,R(x)1 的现象。但是图中,y 操作没有因果序,所以 P3 读到 R(y)2,R(y)1 和 P4 读到 R(y)1,R(y)2 的在 Causal Consistency 是允许的。这一现象,在 Sequential Consistency 是不允许的。不严格地说,Causal Consistency 弱于 Sequential Consistency。
Eventual Consistency(最终一致性)
最终一致性:存储系统保证如果没有新的写操作,那么最终,所有的读操作都能读到一致的数据,这里强调对一个数据项的修改最终会收敛。从某种意义上讲,最终一致性保证的数据在某个时刻会最终保持一致就像是在说:“人总有一天会死”一样。实际上我们更加关心的是:
- “最终”到底是多久?通常来说,实际运行的系统需要能够保证提供一个有下限的时间范围。
- 多副本之间对数据更新采用什么样的策略?一段时间内可能数据可能多次更新,到底以哪个数据为准?一个常用的数据更新策略就是以时间戳最新的数据为准。
由于最终一致性对数据一致性的要求比较低,在对性能要求高的场景中是经常使用的一致性模型。
Client-Centric(User-Centric) Models
前面我们讨论的一致性模型都是针对数据存储的多副本之间如何做到一致性,考虑这么一种场景:在最终一致性的模型中,如果客户端在数据不同步的时间窗口内访问不同的副本的同一个数据,会出现读取同一个数据却得到不同的值的情况。为了解决这个问题,有人提出了以客户端为中心的一致性模型。以客户端为中心的一致性为单一客户端提供一致性保证,保证该客户端对数据存储的访问的一致性,但是它不为不同客户端的并发访问提供任何一致性保证1。
举个例子:客户端 A 在副本 M 上读取 x 的最新值为 1,假设副本 M 挂了,客户端 A 连接到副本 N 上,此时副本 N 上面的 x 值为旧版本的 0,那么一致性模型会保证客户端 A 读取到的 x 的值为 1,而不是旧版本的 0。一种可行的方案就是给数据 x 加版本标记,同时客户端 A 会缓存 x 的值,通过比较版本来识别数据的新旧,保证客户端不会读取到旧的值。
以客户端为中心的一致性包含了四种子模型:
- 单调读一致性(Monotonic-Read Consistency):如果一个进程读取数据项 x 的值,那么该进程对于 x 后续的所有读操作要么读取到第一次读取的值要么读取到更新的值。即保证客户端不会读取到旧值。
- 单调写一致性(Monotonic-Write Consistency):一个进程对数据项 x 的写操作必须在该进程对 x 执行任何后续写操作之前完成。即保证客户端的写操作是串行的。
- 读写一致性(Read-your-Writes Consistency):一个进程对数据项 x 执行一次写操作的结果总是会被该进程对 x 执行的后续读操作看见。即保证客户端能读到自己最新写入的值。
- 写读一致性(Writes-follow-Reads Consistency):同一个进程对数据项 x 执行的读操作之后的写操作,保证发生在与 x 读取值相同或比之更新的值上。即保证客户端对一个数据项的写操作是基于该客户端最新读取的值。
一致性的代价
回头看下 CAP 定理关于可用性的定义,其中并没有对响应时限做出约束。如果一个客户端请求的响应非常非常慢,但是最终得到了响应,在 CAP 的范畴下,这仍然是具有可用性的。更广义的可用性,应该是在约定时限的要求下做出响应。现实中,人们往往是非常关心响应时间的。我们将看到,强一致性的代价就是相对高的响应时长8。
在理论计算机科学中,除了为人熟知的 CAP 定理之外,还有一个叫做 PACELC 的定理,这个定理是 CAP 定理的一个扩展定理。PACELC 定理的命名方式和 CAP 如出一辙,我们来看下这个定理的含义:
当分区(Partition)发生的时候,必须在可用性(Availability)和一致性(Consistency)中做选择;否则(Else),当分区不发生时,必须在响应时长(Latency)和一致性(Consistency)中做选择。
前半句的意思,就是 CAP 定理本身。后半句则指出了:无分区的情况下,要追求更强的一致性,就要接受更高的响应时长。
协议比较
在分布式领域,有多重数据同步协议来保证多副本的一致性,这里9有一张它们在各个维度的比较:
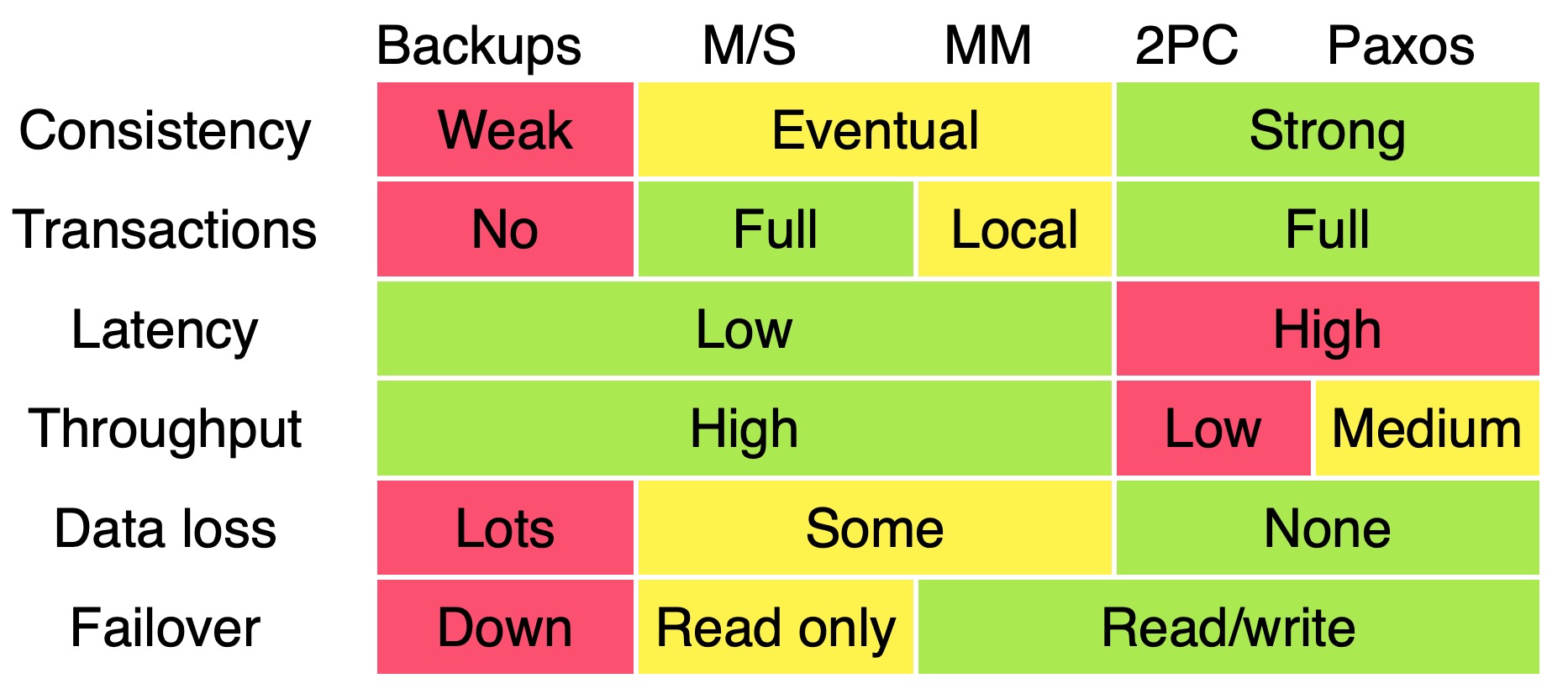
- Backups,冷备份,通常不会用在生产环境
- M/S - master/slave,可以异步,也可以同步,写是瓶颈点;
- MM - multi-master,可以解决写的问题,复杂度在于如何解决冲突;
- 2PC - 2 Phase Commit,强一致,性能低,容易死锁;
关于使用 2PC 来保证线性一致性的说法:2PC 和 3PC 是分布式事务领域的概念,是用来实现分布式事务,而事务的存在主要是保证数据库本身的内部一致性。Linearizability 在前文强调过,是针对 single-object 以及 single-operation 的模型而定义。但是 PAXSO 中也包含了 2PC 的思想,因此 2PC 需要根据上下文来理解。
数据库 ACID
根据开篇的叙述,上面讨论的一致性模型与数据库的 ACID 并无任何联系,因为前面的一致性模型主要针对single-object、single-operation的范畴,但是数据库中讨论的是multi-object、multi-operation的范畴,但是大家经常再不同的文章会看到下图,将两个范畴的内容牵扯在一起。
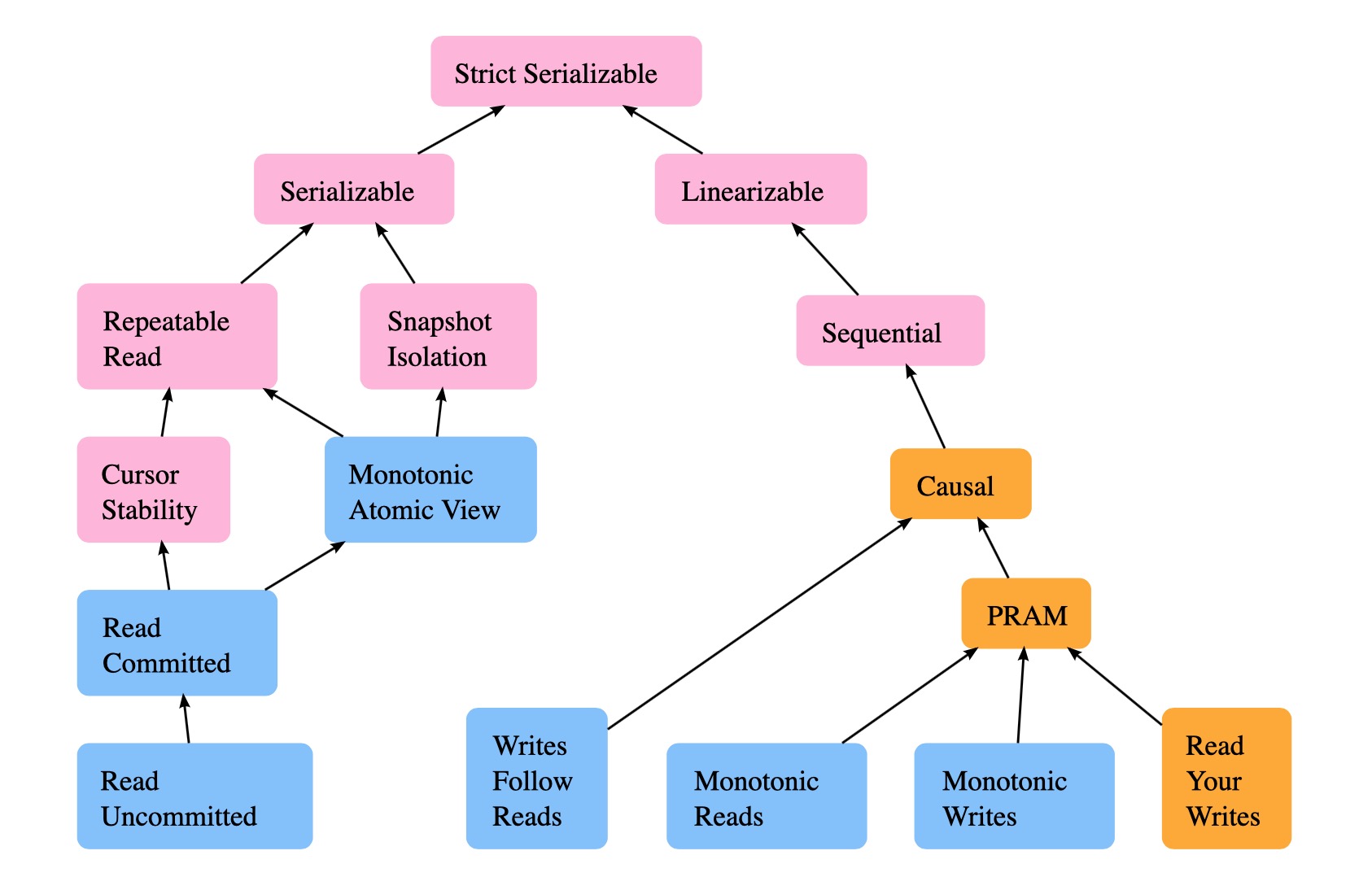
首先要明确的,上图只是为了讨论不同模型的可用性,才将它们绘制在一起的,不同颜色、层级代表了可用性的高低,其主要分为两个枝干,也表明了它们来自两个不同的领域。从一致性的角度来看,将它们放在一起是没有意义的,因为它们是不同抽象层的概念。一个分布式系统正确实现了线性一致性共识算法并不意味着能多数据/事务上能够实现线性一致性。共识算法只能保证多个节点对某个对象的状态是一致的,以 Raft 为例,它只能保证不同节点对 Raft Log(以下简称 Log)能达成一致。那么 Log 后面的状态机(state machine)的一致性呢?如果 Log 后面的状态机是异步应用的,则也无法时每个节点的状态机是实时同步的,从而丧失业务层面的一致性。
类似的比较可以参考《Linearizability versus Serializability》
参考
文档信息
- 本文作者:Neal Hu
- 本文链接:https://lrita.github.io/2019/10/12/consistency-models/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)