最近把收藏的一些关于分布式锁的文件进行一些总结,此文章已经拖了一年多,原本多种分布式锁算法逐一分析的内容已不新鲜,则只保留一些结论性的内容。
通常业务中采用分布式锁主要基于两种需求1:
- 效率性,减少一些重复性劳动,通常锁的持有者进行一些复杂的工作,其他实例共享成功;
- 正确性,与常见的内存中的锁类似,主要起排他性,避免多个实例之间没有互斥逻辑导致逻辑错误。
人们通常更厌恶死锁,所以通常分布式锁都是基于租约的可自动释放的实现。在这种实现下,如果共享资源不参与判断锁的有效性时,采用分布式锁来保护共享资源是不可靠的。
在各种业务逻辑中,使用分布式锁的姿势通常是:
dlock = acquire_dlock(); (1)
...
dlock.is_valid_or_abort(); (2)
access_remote_resource(); (3)
...
dlock.release(); (4)
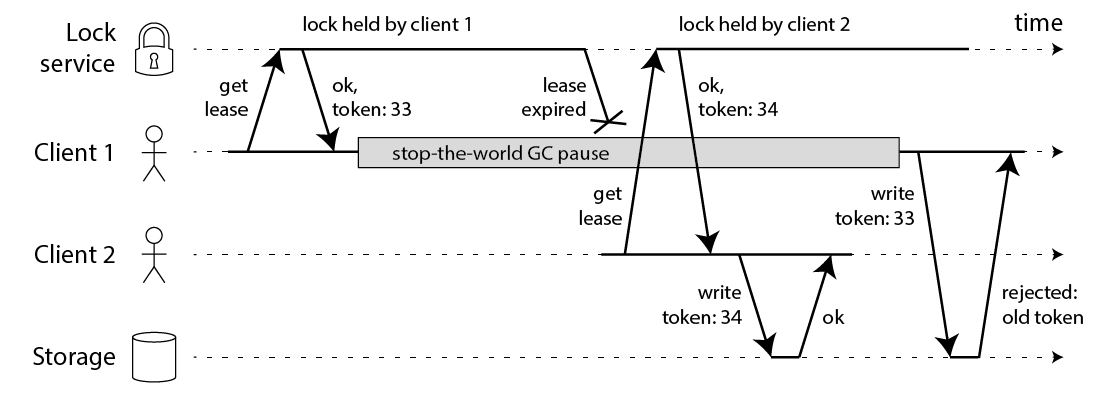
无论什么语言,只要是非实时的操作系统,在(2)(3)之间都有可能产生一个较大时间的程序停滞,可能是 GC、系统调度、网络延时等,都会造成已经持有的分布式锁的超时、自动释放,于此同时,该分布式锁会被其他实例获取,再次进入临界区,操作排他性的逻辑失败。在关于基于Redis实现的分布式锁的讨论中1 2(关于讨论的解读,可以参考3),正反双方都认可该问题,不仅仅是Redis,基于zookeeper、etcd等实现的分布式锁都会出现该问题。
那是不是所有的分布式锁都不可信任了,如何解决这种问题?在1中提出的fencing token,在4提到的Chubby的解决方案,可以大致分为两类:
- 第三视角判断锁的有效性。在系统之外选出一个第三者,来判断系统中谁持有的锁是有效的,这个第三者,可以是资源本身、也可以是完全独立的第三者。
- 锁间延时规避。如果发生分布式锁自动释放事件后,分布式锁管理者在颁发一下锁授予之间增加一个延时(lock-delay),这个延时事件足以使上一个锁持有者完成预设的处理逻辑。白话来讲就是在异常发生后,大家先退避一段时间,避免临界区冲突。
通常来说,第一个方案更正确和高效,第二个方案更简单,但是效率低。
参考
文档信息
- 本文作者:Neal Hu
- 本文链接:https://lrita.github.io/2020/02/20/distributed-lock/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)