最近看了 Simple, Fast, and Practical Non-Blocking and Blocking Concurrent Queue Algorithms1,是一篇 1996 年的关于高效并发队列的论文,是一篇简单而易懂的 lock-free 算法入门佳作。
该论文中介绍了一种单端链表构成的队列数据结构,其采用了两个指针分别指向队列的首尾部分,同时添加一个dummy空白节点,这样就极大概率避免了首位指针同时指向一个节点的概率,减少了竞争概率。其提供了有锁和无锁两个版本的实现:
有锁实现
package x
import (
"sync"
"sync/atomic"
"unsafe"
)
type Node struct {
Next *Node
Value interface{}
}
type Queue struct {
// 其首尾指针分别用一个锁为维护其并发安全
H_lock sync.Mutex
T_lock sync.Mutex
Head *Node
Tail *Node
}
func NewQueue() *Queue {
n := &Node{} // dummy 节点
return &Queue{
Head: n,
Tail: n,
}
}
func (q *Queue) Enqueue(v interface{}) {
node := &Node{Next: nil, Value: v}
q.T_lock.Lock()
// release-store,q.Tail.Next 指针并不被 T_lock 保护,因此仍然需要使用 atomic 操作
// 因为是单端链表,所以只需要使用 release-store atomic 操作就可以保证 Dequeue() 操作
// 时内存可见性的并发问题。Enqueue() 操作由 T_lock 互斥进行保证。
atomic.StorePointer((*unsafe.Pointer)(unsafe.Pointer(&q.Tail.Next)),
unsafe.Pointer(node))
q.Tail = node
q.T_lock.Unlock()
}
func (q *Queue) Dequeue() interface{} {
q.H_lock.Lock()
// acquire-load,q.Head.Next 指针并不被 H_lock 保护,因此仍然需要使用 atomic 操作
node := (*Node)(atomic.LoadPointer((*unsafe.Pointer)(unsafe.Pointer(&q.Head.Next))))
if node == nil {
q.H_lock.Unlock()
return nil
}
v := node.Value
q.Head = node
q.H_lock.Unlock()
return v
}
有锁版本简单易懂,无需多言。其最主要的特点就是,用两个锁,减少了Enqueue和Dequeue之间的互斥和数据竞争,从而提高效率。其源码可以参考github.com/lrita/xdemo/michael_queue/y,在 32 核 CPU 上benchmark可以参考(通常来说,CPU 核心数越高,测试速度越慢,特别是 NUMA 架构的):
goos: linux
goarch: amd64
BenchmarkQueue-32 5000000 341 ns/op 12 B/op 0 allocs/op
BenchmarkQueue-32 5000000 321 ns/op 11 B/op 0 allocs/op
BenchmarkQueue-32 5000000 354 ns/op 11 B/op 0 allocs/op
PASS
无锁实现
其无锁实现保证基本的progress,不受线程调度的影响,但可能存在饥饿,是真正意义上的lockfree算法,其论文中直接给出的是优化版本,不利于简单理解,下面先给出简化版本,然后在给出优化版本:
简化版本
package y
import (
"sync/atomic"
"unsafe"
)
type Node struct {
Next *Node
Value interface{}
}
type Queue struct {
Head *Node
Tail *Node
}
func NewQueue() *Queue {
n := &Node{}
return &Queue{
Head: n,
Tail: n,
}
}
func (q *Queue) EnqueueNotOptimized(v interface{}) {
ok := false
node := &Node{Next: nil, Value: v}
for !ok {
tail := (*Node)(atomic.LoadPointer((*unsafe.Pointer)(unsafe.Pointer(&q.Tail)))) // acquire-load
ok = atomic.CompareAndSwapPointer((*unsafe.Pointer)(unsafe.Pointer(&tail.Next)), nil, unsafe.Pointer(node)) // ①
atomic.CompareAndSwapPointer((*unsafe.Pointer)(unsafe.Pointer(&q.Tail)), // ②
unsafe.Pointer(tail), atomic.LoadPointer((*unsafe.Pointer)(unsafe.Pointer(&tail.Next))))
}
}
func (q *Queue) DequeueNotOptimized() (v interface{}) {
ok := false
for !ok {
head := (*Node)(atomic.LoadPointer((*unsafe.Pointer)(unsafe.Pointer(&q.Head)))) // acquire-load
tail := (*Node)(atomic.LoadPointer((*unsafe.Pointer)(unsafe.Pointer(&q.Tail)))) // acquire-load
next := (*Node)(atomic.LoadPointer((*unsafe.Pointer)(unsafe.Pointer(&head.Next)))) // acquire-load
if next == nil {
return nil
}
ok = atomic.CompareAndSwapPointer((*unsafe.Pointer)(unsafe.Pointer(&q.Head)),
unsafe.Pointer(head), unsafe.Pointer(next)) // ①
if ok {
v = next.Value
}
if head == tail {
atomic.CompareAndSwapPointer((*unsafe.Pointer)(unsafe.Pointer(&q.Tail)),
unsafe.Pointer(tail), atomic.LoadPointer((*unsafe.Pointer)(unsafe.Pointer(&tail.Next)))) // ②
}
}
return v
}
首先,分析EnqueueNotOptimized,其基本实现就是一个尝试-失败-重试的模型,其实现的语义与有锁版本一样:
- 获取当前尾指针
Tail指向的节点; - 然后修改尾节点的后继指针 ①;
- 修改尾指针
Tail指向新的尾节点 ②。
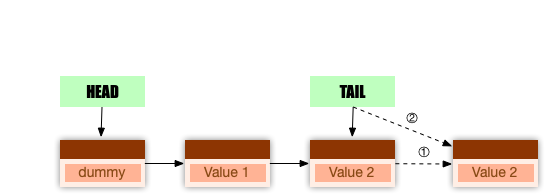
需要注意的是 ② 语句如此特殊的原因是,在实现其基本功能的同时,也保证了整体算法的progress。① 返回成功,就意味着尾节点插入成功,如果此时线程异常或者被调度器阻塞,尾指针Tail就不能及时得到更新,则此时如果其他调用者也调用该方法时,虽然 ① 可能失败,但是仍然会执行 ②,帮助之前未完成的EnqueueNotOptimized调用更新尾指针Tail,因此保证了算法上的progress。
DequeueNotOptimized基本实现也是一个尝试-失败-重试的模型,由于dummy节点的存在,则头指针Head永远不会为空:
- 先依次取出头指针
Head指向的节点、尾指针Tail和后继节点; - 然后更新
Head指向后继节点 ①,如果成功,获取节点成功,读取其值; - 然后
Head和Tail相当,说明队列未空,尝试辅助算法progress②。
EnqueueNotOptimized和DequeueNotOptimized都有辅助算法progress的机制,从而保证了lock-free语义。
优化版本
原论文中直接给出的是优化版本的代码,其主要的优化方向就是尽量减少内存总线的竞争和缓存失效,减少无效的CAS操作(读操作的效率远高于CAS,宁可多进行几次读操作,从而减少不必要的CAS):
func (q *Queue) Enqueue(v interface{}) {
ok := false
node := &Node{Next: nil, Value: v}
for !ok {
tail := (*Node)(atomic.LoadPointer((*unsafe.Pointer)(unsafe.Pointer(&q.Tail)))) // acquire-load
next := (*Node)(atomic.LoadPointer((*unsafe.Pointer)(unsafe.Pointer(&tail.Next)))) // acquire-load
// 如果不相等,表示 tail 和 next 的值已经是不新鲜的了,可以直接重试,需要后续的CAS操作
if tail == (*Node)(atomic.LoadPointer((*unsafe.Pointer)(unsafe.Pointer(&q.Tail)))) {
if next == nil { // 如果next不为nil,说明正有一个Enqueue操作在运行中,放弃本次CAS尝试
ok = atomic.CompareAndSwapPointer((*unsafe.Pointer)(unsafe.Pointer(&tail.Next)), nil, unsafe.Pointer(node))
}
// 辅助算法progress,不可缺少,也不可移动到next == nil的区域,否则就形成了一个事实上的锁
atomic.CompareAndSwapPointer((*unsafe.Pointer)(unsafe.Pointer(&q.Tail)),
unsafe.Pointer(tail), atomic.LoadPointer((*unsafe.Pointer)(unsafe.Pointer(&tail.Next))))
}
}
}
func (q *Queue) Dequeue() (v interface{}) {
ok := false
for !ok {
head := (*Node)(atomic.LoadPointer((*unsafe.Pointer)(unsafe.Pointer(&q.Head)))) // acquire-load
tail := (*Node)(atomic.LoadPointer((*unsafe.Pointer)(unsafe.Pointer(&q.Tail)))) // acquire-load
next := (*Node)(atomic.LoadPointer((*unsafe.Pointer)(unsafe.Pointer(&head.Next)))) // acquire-load
// 检测head、next 值是否新鲜
if head == (*Node)(atomic.LoadPointer((*unsafe.Pointer)(unsafe.Pointer(&q.Head)))) {
if head == tail { // 如果队列为空,辅助算法 progress,不必要每次都辅助算法 progress。
if next == nil {
return nil
}
atomic.CompareAndSwapPointer((*unsafe.Pointer)(unsafe.Pointer(&q.Tail)),
unsafe.Pointer(tail), (unsafe.Pointer(next)))
} else {
ok = atomic.CompareAndSwapPointer((*unsafe.Pointer)(unsafe.Pointer(&q.Head)),
unsafe.Pointer(head), unsafe.Pointer(next))
if ok {
v = next.Value
}
}
}
}
return v
}
其源码可以参考github.com/lrita/xdemo/michael_queue/x,在 32 核 CPU 上benchmark可以参考(通常来说,CPU 核心数越高,测试速度越慢,特别是 NUMA 架构的),可以很明显看出他们之间的效率差距:
goos: linux
goarch: amd64
pkg: github.com/lrita/xdemo/michael_queue/x
BenchmarkQueueNotOptimized-32 10000000 165 ns/op 3 B/op 0 allocs/op
BenchmarkQueueNotOptimized-32 10000000 169 ns/op 3 B/op 0 allocs/op
BenchmarkQueueNotOptimized-32 10000000 171 ns/op 3 B/op 0 allocs/op
BenchmarkQueue-32 10000000 124 ns/op 3 B/op 0 allocs/op
BenchmarkQueue-32 10000000 123 ns/op 3 B/op 0 allocs/op
BenchmarkQueue-32 10000000 117 ns/op 3 B/op 0 allocs/op
PASS
ABA 问题 / FREE 问题
单反涉及lock-free算法,不能不慎重考虑CAS可能产生的ABA问题,原论文企图通过指针和版本共同来控制CAS操作,但是又没有说明具体的细节,而且在其给出的伪代码中,并没涉及该重要内容(着实有点偷鸡)。实现指针和版本的控制策略,通常需要一个CAS2或者双字节atomic128来实现,或者利用指针 8 字节对其的特性,将版本信息存储在指针末尾的几个 bit 上。
并且原论文中的伪代码会出现Use-After-Free的问题,因此其伪代码中的free操作也不是通常意义上的free。
要解决该问题,可能还需要依赖Hazard Pointers2等机制,或者依赖用于GC的语言。
参考
文档信息
- 本文作者:Neal Hu
- 本文链接:https://lrita.github.io/2020/04/24/michael-lockfree-queue/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)