看这篇文章之前,可以先简单阅读一下《KVM 虚拟化详解》,可以帮助理解以下的内容。
4 虚拟内存(Virtual Memory)12
处理器的虚拟内存子系统为每个进程提供了虚拟地址空间的实现。这使每个进程都认为它在系统中是独立的。虚拟内存的优势在其他地方有详细描述,因此这里不再复述。相反,本节集中讨论虚拟内存子系统的实现细节和相关代价。
虚拟地址空间由CPU的内存管理单元(MMU)实现。操作系统必须填充页表数据结构(page table data structures),但大多数CPU自己完成其余工作。这实际上是一个相当复杂的机制;理解它的最佳方式是介绍用于描述虚拟地址空间的数据结构。
通常(程序)输入一个虚拟地址让MMU进行翻译(获得对应的物理地址)。通常对其价值几乎没有限制。虚拟地址在32位系统上是32-bit,在64位系统上是64-bit。在某些系统上,例如x86和x86-64,使用的地址实际上包含了另一个层次的间接寻址(内存分段):这些体系结构使用的分段内存寻址,其会向每个逻辑地址添加一个偏移量。我们可以忽略这一部分,它是微不足道的,程序员不必关心内存处理的性能。{x86上的段限制与性能有关,但这是另一回事。}
4.1 最简单的地址转换
有趣的部分是虚拟地址到物理地址的转换。MMU可以逐页重新映射地址。就像地址缓存排列的时候,虚拟地址被分割为不同的部分。这些部分被用来做多个表的索引,而这些表是被用来创建最终物理地址用的。对于最简单的模型,我们只有一级表。
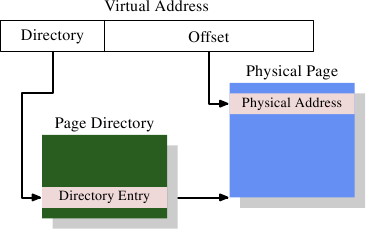
图 4.1: 一层表结构的地址转换
图4.1显示了如何使用虚拟地址的不同部分。顶部用于选择页面目录中的条目;该目录中的每个条目都可以由操作系统单独设置。页面目录条目确定物理内存页面的地址;页面目录中的多个不同条目可以指向同一块物理地址。存储单元的完整物理地址是通过将页面目录中的页面地址与虚拟地址中的低地址相结合来确定的。页面目录条目还包含一些关于页面的附加信息,例如访问权限。
页面目录的数据结构存储在内存中。操作系统必须分配连续的物理内存,并将该内存区域的基址存储在一个特殊的寄存器中。然后,虚拟地址的适当位被用作页面目录的索引,页面目录实际上是一个目录项数组。
举个具体的例子,这是x86机器上4MB页面的布局。虚拟地址的偏移部分大小为22位,足以寻址4MB页面中的每个字节。虚拟地址的剩余10位选择页面目录中的1024个条目之一。每个条目都包含一个4MB页面的10位基址,该基址与偏移量结合形成一个完整的32位地址。
4.2 多级页表
4MB页大小不是标准,它们会浪费大量内存,因为操作系统必须执行的许多操作都需要与内存页面对齐。对于4kB页面(32位机器上的标准,而且通常也是64位机器的标准),虚拟地址的偏移部分大小只有12bit,这将留下20bit作为页表目录的选择器。有2^20个条目的页表是不实用的。即使每个条目只有4个字节,表的大小也将是4MB。由于每个进程都可能有自己独立的页表目录,(那么)系统的大部分物理内存都会被这些页表目录占用。
解决方案是使用多级页表。然后它可以表示一个稀疏的巨大页表目录,在这个目录中,没有实际使用的区域不需要分配内存。因此,这种表示方式更加紧凑,使得在内存中有许多进程的页表而不会对性能造成太大影响。
如今,最复杂的页表结构包括四个层。图4.2显示了这种实现的示意图。
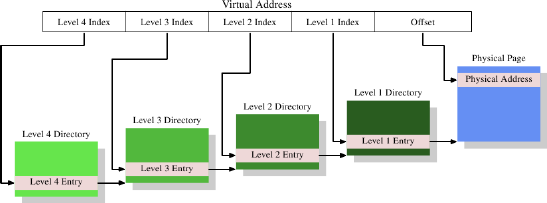
Figure 4.2: 4-层地址转换
在本例中,虚拟地址至少分为五个部分。其中四个部分是各种目录的索引。CPU使用专用寄存器指向第4级目录。4级到2级目录的内容是对下一级目录的引用。如果一个目录条目被标记为空,它显然不需要指向任何较低的目录。这样,页表树就可以稀疏而紧凑。与图4.1一样,1级目录的条目包括部分物理地址,以及访问权限等辅助数据。
为了确定与虚拟地址对应的物理地址,处理器首先确定最高级别目录的地址。该地址通常存储在寄存器中。然后,CPU获取与该目录对应的虚拟地址的索引部分,并使用该索引选择适当的条目。此条目是下一个目录的地址,该目录使用虚拟地址的下一部分编制索引。这个过程一直持续到到达1级目录,此时目录项的值是物理地址的较高部分。物理地址通过从虚拟地址添加页偏移位来完成。这个过程称为页表树遍历。一些处理器(如x86和x86-64)在硬件上执行此操作,其他处理器则需要操作系统的帮助。
系统上运行的每个进程可能都需要自己的页表树。可以部分共享树,但这是个例外。因此,如果页表树所需的内存尽可能小,就有利于性能和可伸缩性。理想的情况是将使用过的内存紧密地放在虚拟地址空间中;实际使用的物理地址(是否紧凑/连续)并不重要。一个小程序可能只需要在2级、3级和4级各使用一个目录,以及几个1级目录。在具有4kB页面和每个目录512个条目的x86-64上,这允许寻址2MB,总共有4个目录(每个级别一个目录)。1GB的连续内存可以通过一个目录寻址,用于级别2到4,512个目录用于级别1。
不过,假设所有内存都可以连续分配,那就太简单了。大多数情况下,出于灵活性的原因,进程的堆栈和堆区域被分配在地址空间几乎相反的一端。这使得任何一个区域都可以在需要时尽可能地增长。这意味着很可能需要两个级别2的目录,相应地,需要更多级别较低的目录。
但即便如此,这也并不总是符合当前的做法。出于安全原因,可执行文件的各个部分(代码、数据、堆、堆栈、DSO(又名共享库))映射到随机地址。随机化延伸到各个部分的相对位置;这意味着进程中使用的各种内存区域在整个虚拟地址空间中都很分布的很广(不会集中到某些地址范围内)。通过对随机地址的位数施加一些限制,可以限制范围,但在大多数情况下,它肯定不允许进程在2级和3级仅使用一个或两个目录运行。
如果性能真的比安全性重要得多,那么可以关闭随机化。操作系统通常至少会在虚拟内存中连续加载所有DSO。
4.3 优化页表访问
页表的所有数据结构都保存在内存中。创建进程或更改页表时,会通知CPU。页表用于使用将每个虚拟地址解析为物理地址。更重要的是:在解析虚拟地址的过程中,每个级别至少使用一个目录。这需要最多四次内存访问(对于正在运行的进程的一次访问),这将导致速度很慢。可以将这些目录表条目视为普通数据,并将它们缓存在L1d、L2等中,但这仍然太慢。
从虚拟内存诞生之初,CPU设计师就采用了特殊的优化方法。一个简单的计算可以表明,只有将目录表条目保留在L1d和更高的缓存中,才会导致糟糕的性能。每个绝对地址计算都需要与页表深度对应的多个L1d访问。这些访问无法并行化,因为它们依赖于前一次查找的结果。在具有四级页表的机器上,仅此一项就至少需要12个周期。再加上L1d未命中的概率,结果是指令管道无法隐藏任何信息。额外的L1d访问还窃取了缓存的宝贵带宽。
因此,不只是缓存页表条目,而是缓存物理页地址的完整计算。出于代码和数据缓存工作的相同原因,这种缓存地址计算是有效的。由于虚拟地址的页偏移部分(页内偏移量)在物理页地址的计算中不起任何作用,因此只有虚拟地址的其余部分用作缓存的标记。根据页面大小,这意味着数百或数千条指令或数据对象共享同一标记,因此物理地址前缀相同。
存储计算值的高速缓存称为Translation Look-Aside Buffer(TLB)。它通常是一个小缓存,但是它必须非常快。与其他缓存一样,现代CPU提供多级TLB缓存;更高级别的缓存更大,速度也更慢。L1TLB的小尺寸通常通过使缓存与LRU逐出策略完全关联来弥补。
如上所述,用于访问TLB的标签(tag,即查找缓存的key)是虚拟地址的一部分。如果标记在缓存中有匹配项,则通过将虚拟地址的页偏移量添加到(读取到的)缓存值来(加合得到)最终的物理地址。这是一个非常快速的过程;必须这样做,因为CPU每条指令需要依赖于内存的物理地址,在某些情况下,还必须使用物理地址作为key进行缓存L2的查询。如果TLB查找未命中,处理器必须执行页表遍历;这可能相当昂贵。
如果地址在另一页上,通过软件或硬件预取代码或数据可能会隐式预取TLB的条目。这不能用于硬件预取,因为硬件可能会启动无效的页表遍历。因此,程序员不能依靠硬件预取来预取TLB条目。因此必须显示使用预取指令(如果需要的时候)。TLB就像数据和指令缓存一样,可以出现在多个级别。与数据缓存一样,TLB通常以两种形式出现:指令TLB(ITLB)和数据TLB(DTLB)。与其他缓存一样,L2TLB等更高级别的TLB通常是统一的。
4.3.1 使用TLB的警告
TLB是处理器核心的全局资源。在处理器核心上执行的所有线程和进程都使用相同的TLB。由于虚拟地址到物理地址的转换取决于安装了哪个页表树,因此如果页表发生更改,CPU不能盲目地重用缓存的条目。每个进程都有不同的页表树(但不是同一进程中的线程),内核和VMM(虚拟机监控程序)也有不同的页表树(如果存在的话)。进程的地址空间布局也可能发生变化。有两种方法可以解决这个问题:
- 每当更改页表树时,TLB都会刷新。
- TLB条目的标记被扩展,以额外且唯一地标识它们所引用的页表树。
在第一种情况下,只要执行上下文切换,就会刷新TLB。由于在大多数操作系统中,从一个线程/进程切换到另一个线程/进程需要执行一些内核代码,因此TLB刷新仅限于进入和离开内核地址空间。在虚拟化系统上,当内核调用VMM并返回时,也会发生这种情况(指TLB刷新)。
刷新TLB有效但代价高。例如,在执行系统调用时,内核代码可能会被限制为几千条指令,这些指令可能会涉及几个新page(或者一个hugepage,就像某些体系结构上的Linux那样)。这项工作只会在触摸页面时替换尽可能多的TLB条目。对于拥有128个ITLB和256个DTLB条目的Intel Core2体系结构,刷新TLB意味着不必要地刷新了100多个条目和200多个条目。当系统调用返回到同一进程时,所有被刷新的TLB条目都可能被再次使用,但它们将不在TLB了。内核或VMM中经常使用的代码也是如此。在进入内核的每个条目上,必须从头开始填充TLB,即使内核和VMM的页表通常不会更改,因此,理论上,TLB条目可以保留很长时间。这也解释了为什么当今处理器中的TLB缓存并不更大:程序很可能不会运行足够长的时间来填充所有这些条目。
当然,这一事实并没有逃过CPU架构师的眼睛。优化缓存刷新的一种可能性是独立分别使TLB条目无效。例如,如果内核代码和数据属于特定的地址范围,则只有属于该地址范围的页面必须从TLB中移出。这只需要比较标签,因此并不十分昂贵。如果地址空间的一部分发生更改,例如通过调用munmap,此方法也很有用。
更好的解决方案是扩展用于TLB访问的标签。如果除了虚拟地址的一部分之外,还为每个页表树(即进程的地址空间)添加了一个唯一标识符,那么TLB根本不需要完全刷新。内核、VMM和各个进程都可以有唯一的标识符。该方案的唯一问题是,TLB标签的可用位数受到严重限制,而地址空间的数量则不受限制。这意味着一些标识符重用是必要的。发生这种情况时,必须部分刷新TLB(如果可能的话)。所有具有重用标识符的条目都必须刷新,但希望这是一个小得多的集合。
当系统上运行多个进程时,这种扩展的TLB标记具有普遍优势。如果每个可运行进程的内存使用(以及TLB项使用)都是有限的,那么当进程再次被调度时,最近使用的TLB项很有可能仍在TLB中。但还有两个额外的优势:
- 特殊的地址空间,比如内核和VMM使用的地址空间,通常只进入使用很短的时间;之后,控制权通常会返回到发起调用的地址空间。如果没有标签(tag),将执行两次TLB刷新。使用标记时,调用地址空间的缓存翻译会被保留,而且由于内核和VMM地址空间根本不经常更改TLB条目,因此以前的系统调用等的翻译仍然可以使用。
- 在同一进程的两个线程之间切换时,根本不需要TLB刷新。如果没有扩展的TLB标签,进入内核切换时会破坏另一个线程的TLB。
一段时间以来,一些处理器已经实现了这些扩展标记。AMD推出了带有Pacifica虚拟化扩展的1-bit标签扩展。在虚拟化环境中,此1-bit Address Space ID(ASID)用于区分VMM的地址空间和guest域的地址空间。这允许操作系统避免在每次输入VMM(例如,为了处理页面错误)时刷新guest的TLB条目,或者在控制返回给guest时刷新VMM的TLB条目。该体系结构将允许在未来使用更多比特。其他主流处理器可能也会效仿并支持这一功能。
4.3.2 影响TLB性能的因素
有几个因素会影响TLB性能。首先是页面的大小。显然,一个页面越大,它容纳的指令或数据对象就越多。因此,较大的页面大小会减少所需的地址转换总数,这意味着TLB缓存中需要的条目更少。大多数架构允许使用多种不同的页面大小;有些尺寸可以同时使用。例如,x86/x86-64处理器的正常页面大小为4kB,但它们也可以分别使用4MB和2MB页面。IA-64和PowerPC允许64kB这样的大小作为基本页大小。
不过,使用大页面会带来一些问题。用于大页面的内存区域在物理内存中必须是连续的。如果管理物理内存的单元大小提高到虚拟内存页的大小,则浪费的内存量将增加。所有类型的内存操作(如加载可执行文件)都需要与页面边界对齐。这意味着,平均而言,每个映射在物理内存中浪费的页面大小是每个映射的一半。这种浪费很容易累积起来;因此,它为物理内存分配的合理单元大小设置了上限。
将单元大小增加到2MB以适应x86-64上的大页面肯定是不现实的。这个尺寸太大了。但这反过来意味着每个大页面必须由许多小页面组成。这些小页面在物理内存中必须是连续的。分配单位页面大小为4kB的2MB连续物理内存可能是一项挑战。它需要找到一个包含512个连续页面的空闲区域。在系统运行一段时间后,物理内存变得碎片化,这可能非常困难(或不可能)。
因此,在Linux上,有必要在系统启动时使用特殊的hugetlbfs文件系统预先分配这些大页面。保留固定数量的物理页面作为大型虚拟页面专用。这会限制可能并不总是被使用的资源。它也是一个有限的池;增加它通常意味着重新启动系统。尽管如此,在追求性能优越、资源充足,hugepage仍然是一种选择。数据库服务器就是一个例子。
增加最小虚拟页面大小(相对于可选的大页面)也有问题。内存映射操作(例如加载应用程序)必须符合这些页面大小。对于大多数架构来说,可执行文件的各个部分的位置具有固定的关系。如果页面大小的增加超出了构建可执行文件或DSO时考虑的范围,则无法执行加载操作。记住这个限制很重要。图4.3显示了如何确定ELF二进制文件的对齐要求。它被编码在ELF程序头中。
$ eu-readelf -l /bin/ls
Program Headers:
Type Offset VirtAddr PhysAddr FileSiz MemSiz Flg Align
...
LOAD 0x000000 0x0000000000400000 0x0000000000400000 0x0132ac 0x0132ac R E 0x200000
LOAD 0x0132b0 0x00000000006132b0 0x00000000006132b0 0x001a71 0x001a71 RW 0x200000
...
Figure 4.3: ELF Program 头部指示对齐要求
在本例中,一个x86-64二进制文件的值为0x200000=2097152=2MB,对应于处理器支持的最大页面大小。
使用较大的页面大小还有第二个效果:页表树的级别数减少。由于虚拟地址中与页偏移量相对应的部分增加,因此不需要通过页目录处理多少位。这意味着,在TLB miss的情况下,需要完成的工作量会减少。
除了使用较大的页面大小,还可以通过将同时使用的数据移动到较少的页面来减少所需的TLB条目数量。这类似于我们上面讨论的缓存使用的一些优化。只是现在,所需的对齐量很大。鉴于TLB条目的数量非常小,这可能是一个重要的优化。
4.4 虚拟化的影响
操作系统映像的虚拟化将变得越来越普遍;这意味着图片中添加了另一层内存处理。进程(基本上是监狱)或操作系统容器的虚拟化不属于这一类,因为只涉及一个操作系统。Xen或KVM等技术可以在有或没有处理器帮助的情况下执行独立的操作系统映像。在这些情况下,只有一个软件可以直接控制对物理内存的访问。
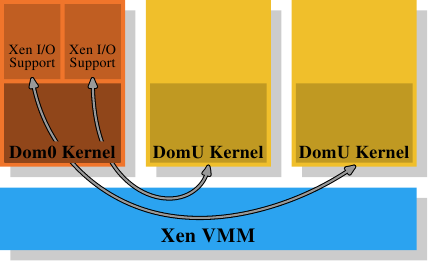
Figure 4.4: Xen虚拟化模型
在Xen的情况下(见图4.4),Xen VMM就是该软件,不过VMM本身并没有实现许多其他硬件控件。与其他早期系统(以及Xen VMM的第一个版本)上的VMM不同,内存和处理器之外的硬件由特权Dom0域控制。目前,这与非特权DomU内核基本相同,就内存处理而言,它们没有区别。这里很重要的一点是,VMM将物理内存分配给Dom0和DomU内核,这些内核本身实现了通常的内存处理,就像它们直接在处理器上运行一样。
为了实现虚拟化完成所需的域分离,Dom0和DomU内核中的内存处理不具有对物理内存的无限制访问。VMM不会通过分发单独的物理页并让guest操作系统处理寻址操作;这不会对错误或恶意的guest域提供任何保护。相反,VMM为每个guest域创建自己的页表树,并使用这些数据结构寻址内存。好处是可以控制对页表树的管理信息的访问。如果代码没有适当的权限,它将无法执行任何操作。
这种访问控制在Xen提供的虚拟化中得到利用,无论是使用准虚拟化还是硬件(也称为完全)虚拟化。guest域为每个进程构建页面表树的方式故意与准虚拟化和硬件虚拟化非常相似。每当guest操作系统修改其页表时,就会调用VMM。VMM然后使用guest域中更新的信息来更新自己的影子页表。这些(影子页表)是硬件实际使用的页面表。显然,这个过程非常昂贵:页面表树的每次修改都需要调用VMM。虽然没有虚拟化,对内存映射的更改并不高效,但现在它们变得更加代价高。
考虑到从guest操作系统到切换到VMM,再切换回本身的更改已经非常代价高,额外的成本可能非常大。这就是为什么处理器开始有附加功能来避免创建影子页表。这不仅是因为速度问题,而且还减少了VMM的内存消耗。英特尔有Extended Page Tables(EPT),AMD有Nested Page Tables(NPT)技术。本质上,这两种技术都有客户操作系统生成虚拟物理地址(注意,不是虚拟地址)的页表,然后,必须使用的EPT/NPT树将这些虚拟物理地址进一步转换为实际的物理地址。这将允许以几乎与无虚拟化情况相同的速度处理内存。它还减少了VMM的内存使用,因为现在每个域只需要维护一个页表树(与进程相反)。
附加功能的地址转换步骤的结果也存储在TLB中。这意味着TLB不存储虚拟物理地址,而是存储查找完的结果。已经有人解释说,AMD的Pacifica扩展引入ASID是为了避免每次进入时TLB刷新。ASID的bit数在处理器扩展的初始版本中为1位;这足以区分VMM和guest操作系统。英特尔的则是虚拟处理器ID(VPID),它们的用途相同,只是数量更多。但是,VPID对于每个guest域都是固定的,因此它不能用于标记单独的进程,也不能避免该级别的TLB刷新。
每个地址空间修改所需的工作量大是虚拟化操作系统的一个问题。不过,基于VMM的虚拟化还存在另一个固有问题:没有办法实现两层内存处理。但内存处理很难(特别是在考虑NUMA等复杂因素时,请参见第5节)。使用单独VMM的Xen方法使得优化(甚至是良好的)处理变得困难,因为内存管理实现的所有复杂性,包括内存区域发现等“琐碎”事情,都必须在VMM中复制。操作系统拥有成熟且优化的实现;人们真的希望避免重复它们。
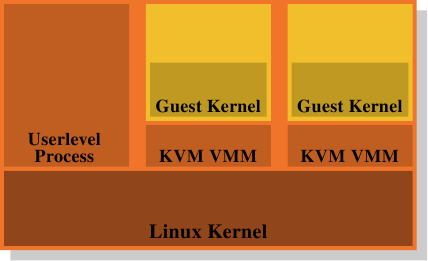 Figure 4.5: KVM虚拟化模型
Figure 4.5: KVM虚拟化模型
这就是为什么总结VMM/Dom0模型是如此有吸引力的选择。图4.5显示了KVM Linux内核扩展如何解决这个问题。没有单独的VMM直接在硬件上运行并控制所有guest;相反,一个普通的Linux内核接管了这个功能。这意味着Linux内核中完整而复杂的内存处理功能用于管理(虚拟化)系统的内存。guest域与正常的用户级进程一起运行,创建者称之为“guest mode”。虚拟化(准虚拟化或完全虚拟化)由另一个用户级进程(KVM VMM)控制。这只是另一个使用内核实现的特殊KVM设备控制来guest的过程。
与Xen模型的单独VMM相比,该模型的好处在于,即使在使用guest操作系统时仍有两个内存转换机制在工作,但只需要一个实现,即Linux内核中的实现。无需在另一段代码(如Xen VMM)中复制相同的功能。这会导致更少的工作、更少的错误,并且可能会减少两个内存处理程序接触的摩擦,因为Linux客户机中的内存处理程序与运行在裸硬件上的外部Linux内核中的内存处理程序做出相同的假设。
总的来说,程序员必须意识到,使用虚拟化后,内存操作的成本至少比不使用虚拟化时要高。任何减少这项工作的优化都将在虚拟化环境中获得更大的回报。随着时间的推移,处理器设计师将通过EPT和NPT等技术越来越多地减少差异,但这种差异永远不会完全消失。
参考
文档信息
- 本文作者:Neal Hu
- 本文链接:https://lrita.github.io/2022/04/01/programmer-should-know-about-memory-2/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)