CRC 算法
循环冗余校验-CRC是常用的一种校验数据一致性的算法。关于其原理与发展可以参考其维基百科。
关于该算法的优化也经常是大家关心的一个方向,现在最常用的实现基本都是查表法,下图是别人总结的相关算法的优化历史1:
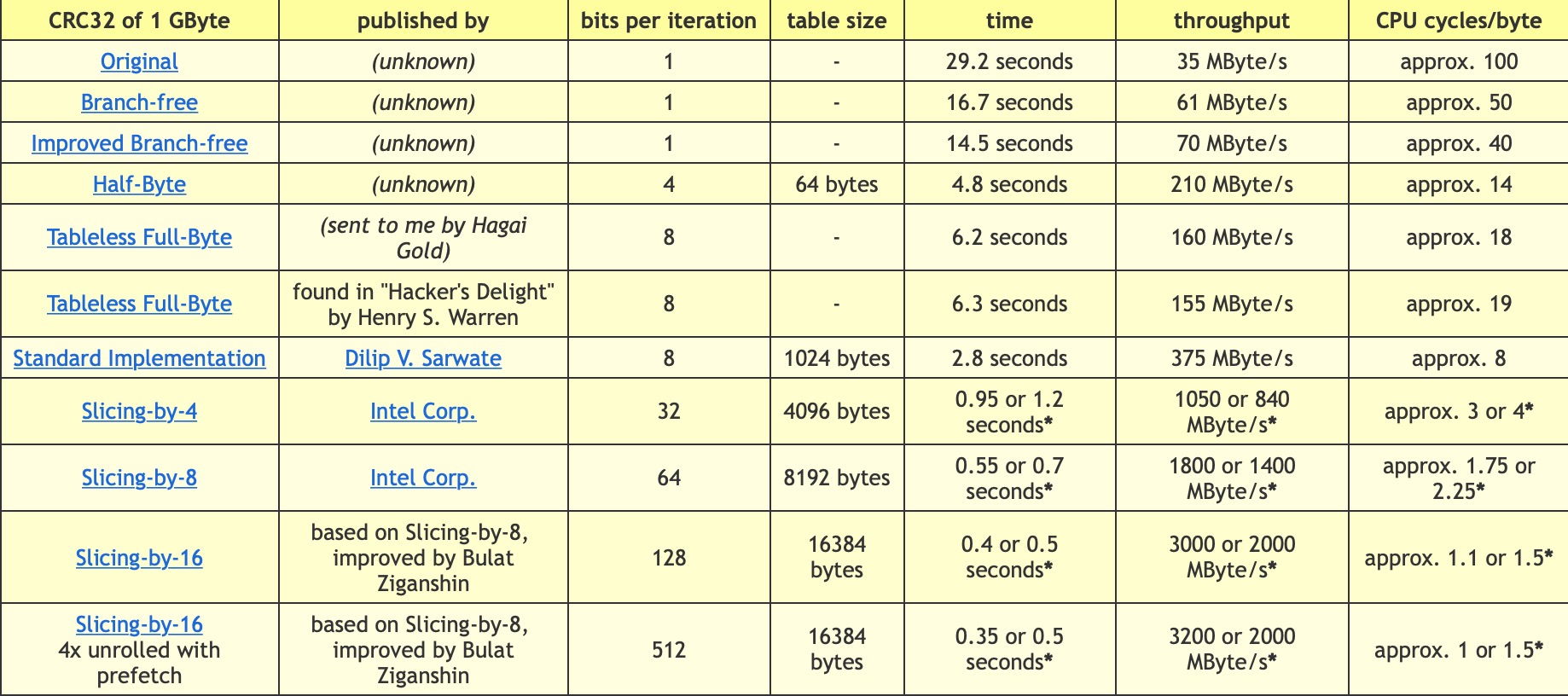
可以看出,当因特尔提出了slice-by-x的优化后,其速度得到的飞跃。
然而 CRC 算法的变种数量非常之多,但是已经被实现的那些优化只是少数的几种,比如ISO、ECMA等。同时这些优化后的代码已经丢失的大量中间过程,是的其难以被移植到其他变种之上。
优化变种算法
经过一番研究考证,CRC64 变种采用slice-by-x优化的主要步骤为:
- 将原始查询表转化为 8 重表格
// table[0] 是原始查询表, table[1...7] 是生成的8重表格
for (n = 0; n < 256; n++) {
crc = table[0][n];
for (k = 1; k < 8; k++) {
crc = table[0][crc & 0xff] ^ (crc >> 8);
table[k][n] = crc;
}
}
- 优化 CRC 算法,每个循环计算 8 个字节
while (len >= 8) {
crc ^= *(uint64_t *)byte; // 小端计算方式
crc = table[7][crc & 0xff] ^
table[6][(crc >> 8) & 0xff] ^
table[5][(crc >> 16) & 0xff] ^
table[4][(crc >> 24) & 0xff] ^
table[3][(crc >> 32) & 0xff] ^
table[2][(crc >> 40) & 0xff] ^
table[1][(crc >> 48) & 0xff] ^
table[0][crc >> 56];
byte += 8;
len -= 8;
}
while (len) {
crc = table[0][(crc ^ *byte++) & 0xff] ^ (crc >> 8);
len--;
实现
github.com/lrita/crc64采用上述方法,优化了redis使用的 CRC64 变种算法,使其速度从381.29 MB/s提升到1474.16 MB/s.
PYCRC
pycrc2可以生成不同变种 CRC 算法的优化 C 代码,变种的核心参数可以通过参数--width --poly --reflect-in --xor-in --reflect-out --xor-out进行相应调整。支持的优化算法有bit-by-bit, bbb, bit-by-bit-fast, bbf, table-driven, tbl等。例如:
./pycrc.py --generate=c --algorithm=table-driven --model=crc-32 --slice-by=4
参考
文档信息
- 本文作者:Neal Hu
- 本文链接:https://lrita.github.io/2019/04/20/optimize-crc-variants/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)