简介
PacificA 是微软为大规模分布式存储系统开发的一个通用复制框架。其简单描绘了一种可以实现强一致性的多副本数据复制的框架,框架中的每个模块,用户可以自行实现。其相对于其他协议(PAXSO/RAFT)突出特点就是简洁、易于理解和实现,并且对于append-only类型的数据同步尤其高效,同时容错性更高。
特点
- 聚焦于单一局域网(LAN)网络环境,跨机房不友好(因为其每个更新操作需要同步到每个副本,不同于 PAXSO/RAFT 只需要同步到多数节点,整体速度取决于最慢的副本速度);
- 假设所有的故障都是停机故障(fail-stop),没有拜占庭问题;
- 配置管理与数据复制分离,配置管理可以是一个抽象的配置中心服务,可以依赖 zookeeper、etcd 等现有组件来实现;
- 去中心化故障检测;
primary/backup的数据复制模型,log-based的存储模型。
架构
在该框架内,实例可以分为配置服务集群和数据存储集群。
- 数据存储集群:负责系统数据的读取和修改,通过使用多副本方式保证数据可靠性和可用性;
- 配置服务集群:维护副本配置信息,参与故障探测判定。
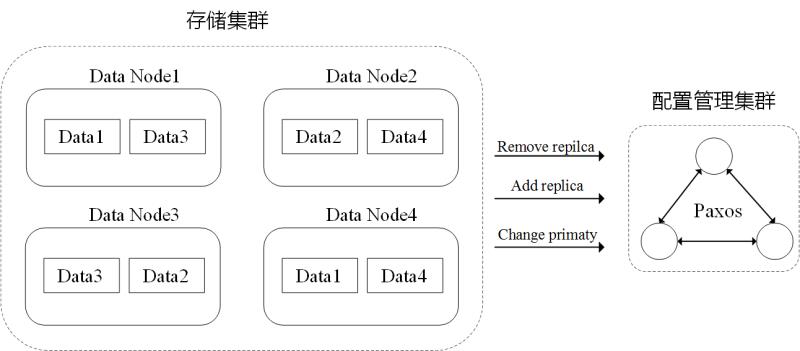
多副本数据同步
首先,为了提升系统的整体吞吐,可以将数据存储集群中的实例分为多个复制组(Replica Group),每个复制组内保持数据同步与一致性。
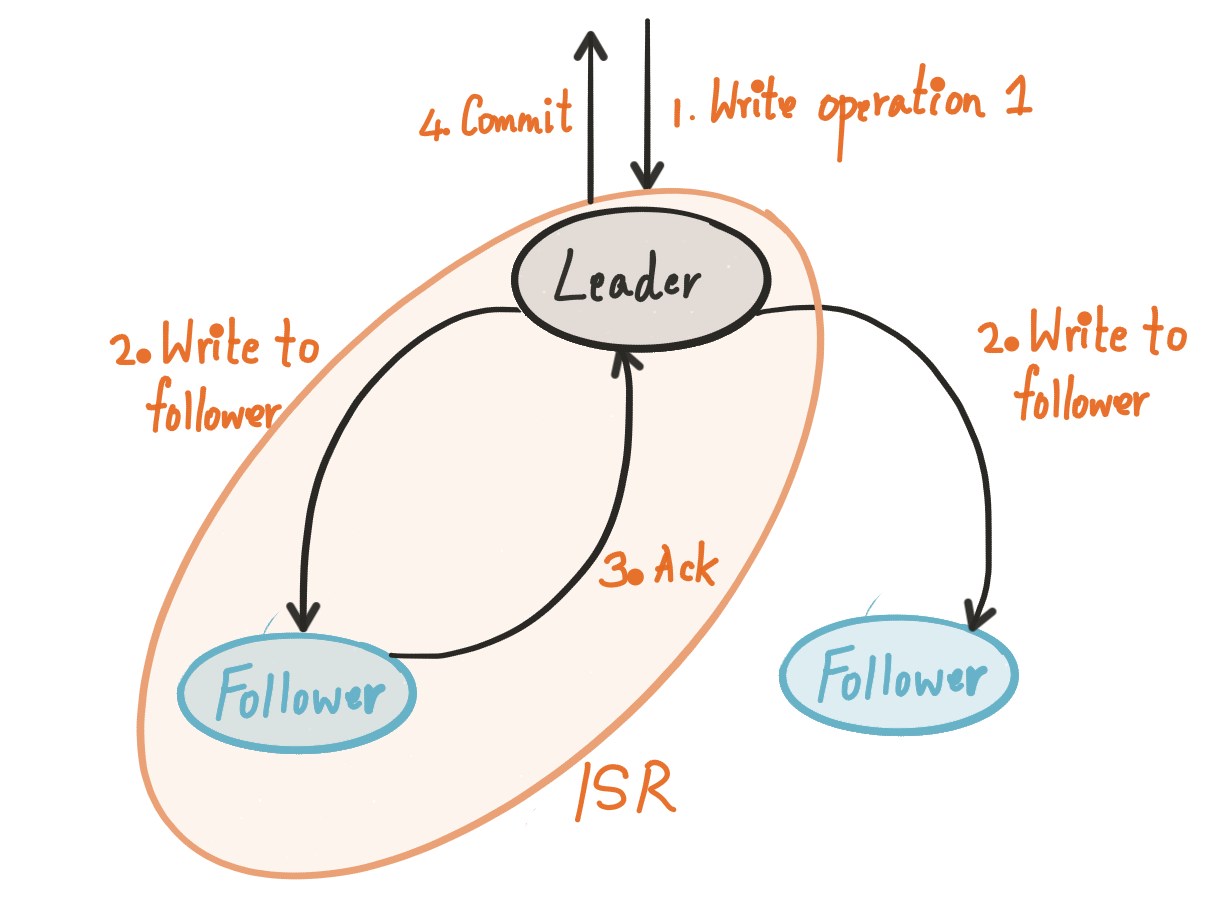
在复制组内,数据同步采用主从范式(Primary/Backup Data Replication),所有客户端的读写请求都会被发送到主节点上进行处理。因此在绝大多数情况下,从节点都是轻负载的状态,因此通常会将主从身份混合分布在一起:
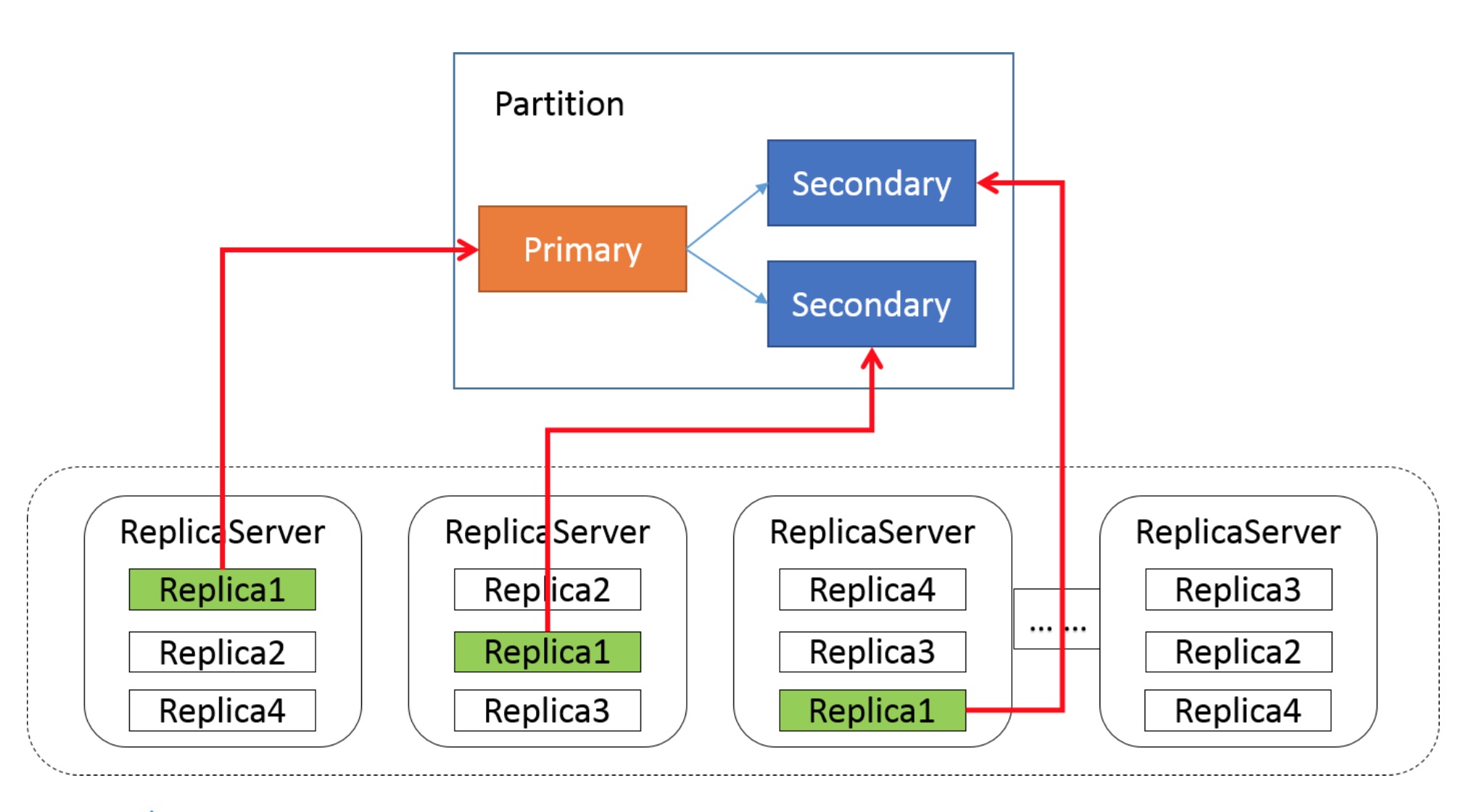
在主从副本之间通过类似二阶段提交的方式进行数据复制与确认:
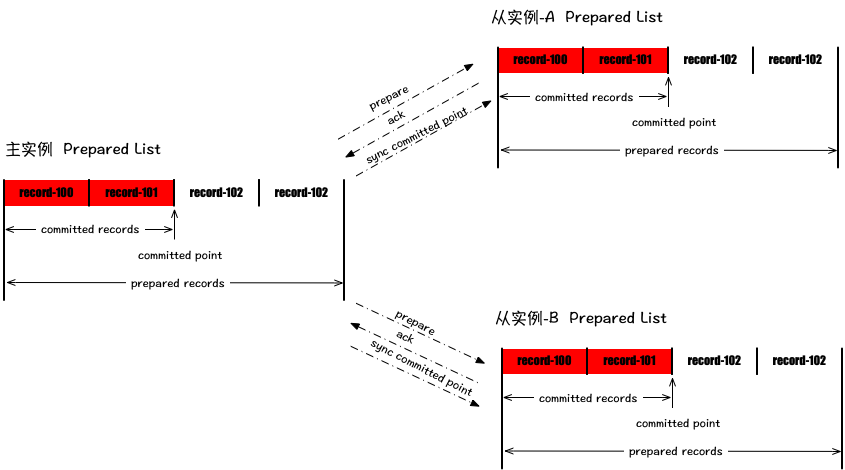
- 其每个副本在可持久化存储上维护一个prepared list和committed point记录;
- 客户端的每个写请求在主副本上给分配一个单调递增的序号(serial number),然后放入prepared list中,主副本会将prepared list中的记录按顺序依次同步给每个从副本。
- 从副本一旦受到主副本同步过来的记录,会返回给主副本一个ack消息。
- 当主副本prepared list某个位置之前的全部消息都同步给所有从副本后,则主副本移动自身的committed point记录,并且将其同步给所有的从副本。
当然,为了提高效率,同步 prepare record 和同步 committed point 两种请求可以异步 pipeline 进行。 为了保证强一致性,prepared list中未committed的记录需要是可以被回滚或截断的,这一点后面会讲到。
配置管理
类似 PAXSO/RAFT 都是将配置变更当做一种特殊类型的 log 在节点间进行同步、特殊处理。该设计框架将配置管理从同步协议中剥离出来交给一个配置服务集群,中心化处理,极大地简化了设计:
- 复制组(
Replica Group)不在需要考虑配置一致性的协商,充分信任配置服务集群的管理。在一般同步协议中reconfigure是比较难处理的一件事,通常会避免进行反复reconfigure,而将配置交由第三方维护后,则reconfigure会变得很轻量,复制组中很多故障处理都可以采用reconfigure来进行; - 配置服务集群可以采用现有的 zookeeper/etcd 等进行实现,实践上更简单;
- 很大程度上提升可用性,复制组(
Replica Group)中不需要维护配置的一致性,能够保证在任何时刻,都有一个唯一指定的主副本,则能够支持 N-1 个实例宕机。而且配置服务集群只在变更配置、故障检测等情况下才需要使用,分为 2 种角色集群后,整体同时故障的概率降低,也在一定程度上提升了整体个可用性。
租约与故障检测
与大多数方案类似,该框架也采用租约(lease)来维护主副本的任期和避免出现双主的情况,由主副本周期性发送给从副本心跳请求,然后从副本返回ACK请求,并且将租约机制与故障检测结合在一起形成了去中心化的故障检测(简单来说就是在每个复制组内,主从副本互相进行点对点的检测)。
- 当主副本收到最后一次所有从副本的ACK(出现分区故障等,所以从副本不再响应主副本的心跳请求)后超过\(lease\ period\),主副本就认为自身角色已经过期;
- 当主副本认为某些从副本出现故障,或者数据同步速度过慢拖慢整体速度时,可以向配置服务集群发起请求,移除疑似故障的从副本;
- 当从副本超过\(grace\ period\)还未主副本的心跳请求,则认为主副本异常,会向配置服务集群发起请求,请求移除主副本并建议提升自身为主副本;
- 当\(lease\ period < grace\ period\)时可以避免双主的情况产生;
- 当新增副本,后者中途故障的副本重新加入时,向配置服务集群发起请求即可。由于主副本的每个变更请求需要同步到所有从副本,为了保证整个复制组的可用性,建议新增的副本先作为候选者身份(candidate)同步主副本的数据,当prepared list与主副本很接近时,在发起配置变更请求,这样就不会影响整个复制组。
强一致性
- 在通常时刻,每个数据变更请求都会同步到每一个副本,并且所有的读写请求都在主副本进行,则保证线性一致性;
- prepared list和committed point都维护在持久化存储中,在单副本的情况下,只要是可恢复的宕机,都不会丢失数据;
- 当主副本身份切换时,新的主副本会将prepared list所有未committed的记录(record)和序号(sn)同步给全部从副本,从副本们根据自身状态追加或者截断自身的prepared list,使得记录跟新的主副本保持一致。由于主副本将记录同步给全部从副本时才会移动committed point,所以新的主副本prepared list中的记录一定是大于原先的committed point,这样就能保证在任意故障恢复处理中,已经committed point前的记录不会丢失;但是可能会导致记录重复:因为在故障时刻,client 发送的请求可能落入*prepared list*的未*commit*部分,但是 client 不能得到原主副本的响应,在切换主副本后,*prepared list*中的未*commit*部分可能变为*committed*状态,但是 client 还可能重复请求以避免操作遗漏,这样就导致了记录重复。因此建议*prepared list*中存储的 record 是数据转换的状态,而不是过程命令。比如 client 发送的是
a++指令,*prepared list*中记录的应该是set a = 3而不是a++,这样即使记录重复了,也不会有任何影响。 - 当复制组增加一个全新的副本时,该副本现以候选人的身份同步主副本的数据,当追赶上主副本的prepared list时,申请变更配置;
- 当复制组中故障离群的副本回归时,应该先截断prepared list中未committed的记录,然后追赶主副本的数据;
- 综上,committed point之前的数据都是不会丢失的。
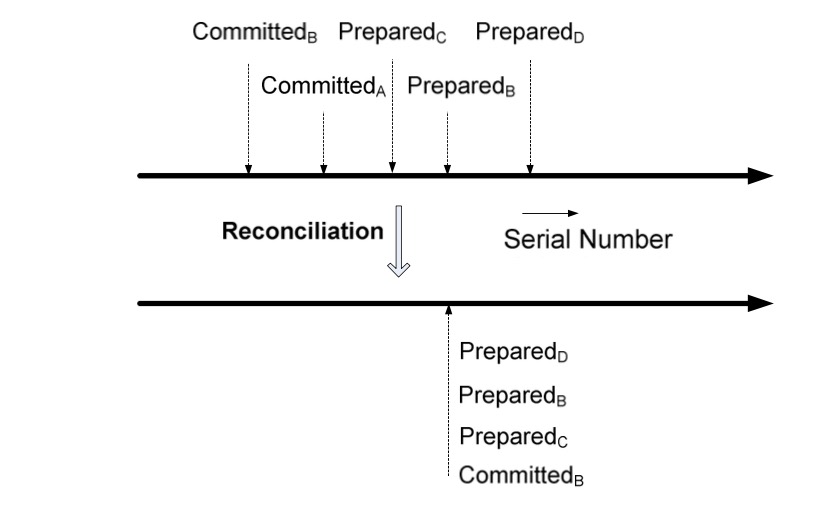
上图是原论文中展示的一个故障恢复的案例,A 是原主副本,所以副本的committed point都位于prepared list尾部之前,当故障发生后,B 接替成为新的主副本,则在仲裁故障恢复后,所有从副本的prepared list保持与新的主副本 B 一致,少的追加同步,多的进行阶段;
实践
采用PacificA框架或者等效原理的开源组件有:
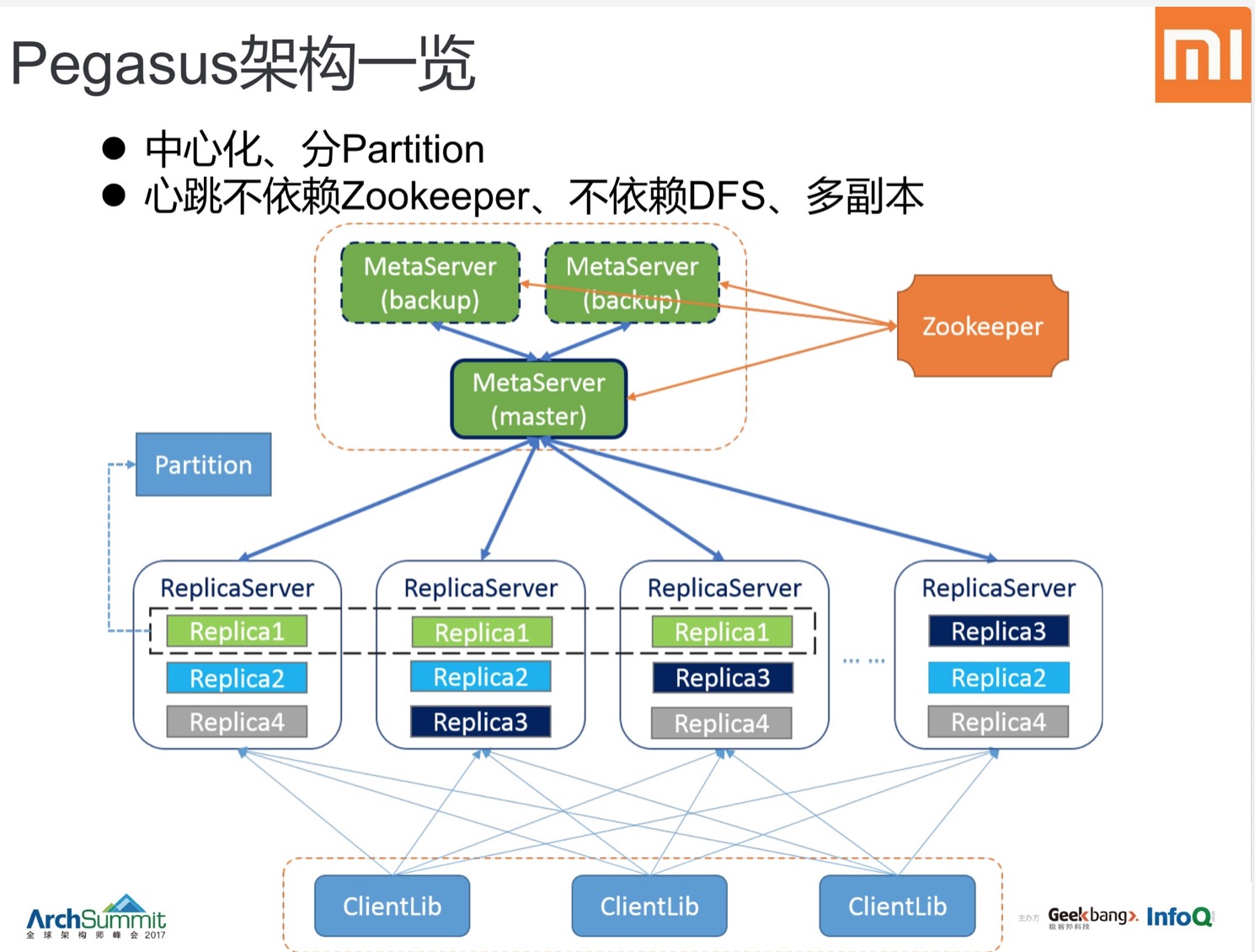
- KAFKA
- Pegasus
参考
文档信息
- 本文作者:Neal Hu
- 本文链接:https://lrita.github.io/2020/02/10/pacific-a-framework/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)